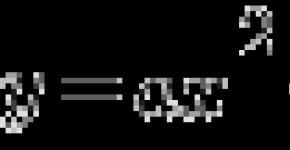The concept of variation in statistics. Variation and variationaries, variation swings
Indicators of variation.When studying the varying sign in units of the set, it is impossible to be limited only by calculating middle size From individual options, since the same average can relate far from the same in the composition of the aggregates.
The variation of the feature is called the difference between the individual values \u200b\u200bof the feature inside the aggregate studied.
The term "variation" occurred from the Latin variatio - a change, volatility, distinction. However, not all sorts of differences are called variation.
Under the variation in statistics, they understand such quantitative changes The values \u200b\u200bof the studied feature within a homogeneous totality, which are due to the intersecting effect of action various factors. The amounts of individual values \u200b\u200bcharacterize the indicators of the variation. The greater the variation, the farther an average of the individual values \u200b\u200blie apart.
There is a variation of a trait in absolute and relative values.
Absolute indicators include: variation variation, linear deviation, average quadratic deviation, dispersion. Everything absolute indicators have the same dimension as the values \u200b\u200bstudied.
Relative indicators include coefficients of oscillation, linear deviation and variation.
Absolute indicators. Let us calculate absolute indicators characterizing the variation of the feature.
The variation variation is the difference between the maximum and minimal sign.
|
R \u003d Xmax - Xmin. |
The scope of the variation is not always applicable, as it takes into account only the extreme signs of the feature that can be very different from all other units.
More accurately, it is possible to determine the variation in a row with the help of indicators that take into account the deviations of all options from the average arithmetic.
Such indicators in statistics are two: medium linear and secondary quadratic deviation.
Middle linear deviation (L) is an arithmetic average of absolute values deviations of individual options from the average.
The practical use of the average linear deviation is as follows, with the help of this indicator the composition of the working, rhythm of production, the uniformity of the supply of materials is analyzed.
The disadvantage of this indicator lies in the fact that it complicates the calculations of the likely type, it makes it difficult to apply the methods of mathematical statistics.
The average quadratic deviation () is the most common and generally accepted indicator of the variation. It is a slightly larger linear deviation. For moderately asymmetric distributions, the following ratio has been established between them.
For its calculus, each deviation from the middle is built into the square, all squares are summed up (taking into account weight), after which the sum of the squares is divided into the number of row members and the square is retrieved.
All these actions expresses the following formula
those. The average quadratic deviation is a square root of the middle arithmetic squares of deviations from the average.
The average quadratic deviation is the meril of the reliability of the average. The smaller σ, the better the arithmetic average reflects the entire present combustion.
The average arithmetic of the squares of the deviations of the values \u200b\u200bof the signs from the average value is the name of the dispersion (), which is calculated by the formulas
A distinctive feature this indicators is that when taking a square () specific gravity Small deviations decrease, and large increases in the total amount of deviations.
The dispersion has a number of properties, some of them allow you to simplify its calculation:
1. The dispersion of a constant value is 0.
If, then.
Then  .
.
2. If all the variants of the values \u200b\u200bof the feature (x) decrease on the same number, then the dispersion will not decrease.
Let, but then in accordance with the properties of the middle arithmetic and.
The dispersion in the new row will be equal
Those. The dispersion in the row is equal to the dispersion of the initial row.
3. If all the options for signs are reduced to the same number of times (k times), the dispersion will decrease in the K2 times.
Let, then.
The dispersion of the new row will be equal

4. The dispersion calculated with respect to the middle arithmetic is minimal. The average square of deviations, calculated relative to an arbitrary number, is greater than the dispersion calculated relative to the middle arithmetic, on the square of the difference between the average arithmetic and number, i.e. ![]() . The dispersion from the average has a minimal property, i.e. It is always less dispersions calculated from any other values. In this case, when we equate to 0 and, therefore, do not calculate the deviations, the formula takes such a form:
. The dispersion from the average has a minimal property, i.e. It is always less dispersions calculated from any other values. In this case, when we equate to 0 and, therefore, do not calculate the deviations, the formula takes such a form:
Above the calculation of the indicators of variations for quantitative signs, but economic calculations There may be a task of assessing the variation of high-quality signs . For example, when studying the quality of manufactured products, the products can be divided into high-quality and defective.
In this case we are talking On alternative features.
Alternative features are called such units of the totality, and others are not. For example, the presence of production experience in applicants, a degree in university teachers, etc. The presence of a sign in units of aggregate is conventionally denoted by 1, and the absence of 0. Then, if the share of units with a sign (in the total number of units of aggregate), refer to P, and the share of units that do not have a sign, through q, the dispersion of an alternative feature can be Calculate by general rule. In this case, P + Q \u003d 1 and, therefore, Q \u003d 1- p.
First, we calculate the average value of an alternative feature:
Calculate the average alternative sign
![]() ,
,
those. The average value of an alternative feature is equal to the proportion of units with this feature.
The dispersion of the same alternative feature will be equal to:
Thus, the dispersion of an alternative feature is equal to the work of the shares of units with this feature, the share of units that do not have this feature.
A secondary quadratic deviation will be equal \u003d.
Relative indicators. For the purposes of comparing the amounts of different signs in the same combination or, when comparing the amounts of the same character, in several aggregates, indicators of variations expressed in relative values \u200b\u200bare of interest. The database for comparison is the average arithmetic. These indicators are calculated as the ratio of the variation variation, the average linear deviation or the average quadratic deviation to the middle arithmetic or median.
Most often, they are expressed as a percentage and determine not only a comparative estimate of the variation, but also give the characteristic of the uniformity of the aggregate. A set is considered homogeneous if the coefficient of variation does not exceed 33%. Distinguish the following relative parameters of variation:
1. The coefficient of oscillation reflects the relative amounts of extreme signs of the sign around the average.
3. The coefficient of variation assesses the typicity of average values.
|
|
The smaller, the nonsense the totality for the studied attribute and is typical of the average. If ≤33%, then the distribution is close to normal, and the totality is considered homogeneous. From the above example, the second set of homogeneous.
Views of dispersions and the rule of addition dispersions.Along with the study of the variation of the feature along the entire totality, as a whole, it is often necessary to trace quantitative changes in the signs of groups to which the totality is divided, as well as between groups. Such a study of the variation is achieved by calculating and analyzing different species Dispersion.
At the same time, it is possible to identify three indicators of the sections of the sign in the aggregate:
1. The overall variation of the aggregate, which is the result of all the reasons. This variation can be measured by a common dispersion (), which characterizes the deviation of individual values \u200b\u200bof a sign of a combination of total average
|
|
 .
.2. The variation of group averages expressing the deviations of group averages from the total average and reflecting the effect of the factor in which the grouping is produced. This variation can be measured by the so-called intergroup dispersion (Δ2)
|
|
 ,
,where - group average, and-summary average for the entire totality, and the number of individual groups.
3. Residual (or intragroup) variation, which is expressed in the deviation of the individual values \u200b\u200bof the feature in each group from their group average and, therefore, reflects the influence of all other factors except for the basis of the grouping. Since the variation in each group reflects a group dispersion
|
|
 ,
,that all the totality, the residual variation will reflect the average of group dispersions. This dispersion is called an average of intragroup dispersions () and it is calculated by the formula
This equality having a strictly mathematical proof is known as a rule of dispersions.
Rule of addition dispersions allows you to find general dispersion According to its components, when the individual values \u200b\u200bof the attribute are unknown, and only group indicators are available at the disposal.
The coefficient of determination. The dispute addition rule allows you to identify the dependence of the results from certain factors using the determination coefficient.
It characterizes the effect of a feature laid in the base of the grouping, on the variation of an effective feature. The correlation relationship varies from 0 to 1. If, the grouping feature does not affect the effective. If, the resulting feature varies only depending on the characteristic of the group, and the influence of other factor signs is zero.
Indicators of asymmetry and excesses.In the field of economic phenomena, strictly symmetric rows are extremely rare, more often have to deal with asymmetric rows.
In statistics, for the characteristics of asymmetry use several indicators. If we consider that in a symmetric row, the average arithmetic matches the value with the fashion and median, the simplest indicator of asymmetry () will be the difference between the average arithmetic and fashion, i.e.
The magnitude of the excess is calculated by the formula
If\u003e 0, then the excess is considered positive (island distribution) if<0, то эксцесс считается отрицательным (распределение низковершинно).
Variation -this is a difference in the values \u200b\u200bof any sign in different units of this totality in the same period or time. The variation indicators include: variation variation, medium linear deviation, dispersion and average quadratic deviation, variation coefficient.
Absolute indicators:
rAM of variation R, Presenting a difference between the maximum and minimum feature values \u200b\u200b:.
The variation variation shows only the extreme deviations of the feature and does not reflect deviations of all options in the row. When studying variations, it is impossible to be limited only by the definition of its scope. An indicator is needed to analyze the variation, which reflects all vibrations of the variation and gives a generalized characteristic. The simplest indicator of this type is the average linear deviation.
Medium linear deviationit is an average arithmetic absolute values \u200b\u200bof deviations of individual options from their average arithmetic (at the same time it is always assumed that the average is subtracted from the option: ()).
The average linear deviation for non-marked data:
,
where n. - the number of members of the series; For grouped data:
,
where - the amount of frequencies of the variational series.
Dispersion The feature is an average square of deviations of variants from their average value, it is calculated using simple and suspended dispersions (depending on the source data).
Simple dispersion for non-marked data:
 ;
;
weighted dispersion for variational series:
.
The dispersion has certain properties, two of which:
1) if all the sign values \u200b\u200bare reduced or increased by the same constant A, then the dispersion will not change from this;
2) If all the sign values \u200b\u200bare reduced or enlarged at the same number of times (i times).
This dispersion will decrease accordingly or increase at times. Using the second dispersion property, dividing all the variants by the size of the interval, can be obtained by the calculation formula dispersions in variational rows with equal intervals by the method of moments:
 ,
,
where -Despers, calculated by the method of moments;
i - the magnitude of the interval;
- new (transformed) values \u200b\u200bof options (A - conditional zero, which is convenient to use the middle of the interval with the highest frequency);
- moment of second order;
- Square of the moment of first order.
Average quadratic deviationequally the root square from the dispersion: for non-bar-by data:
,
for variational series:
 .
.
The average quadratic deviation is a generalizing characteristics of the size of the characterization of the feature in the aggregate; It shows how average the specific options are deflected from their average value; It is an absolute measure of the characteristics of the sign and is expressed in the same units as the options, therefore it is economically well interpreted.
Relative Indicators:
The coefficient of variation represents a percentage of the ratio of the average quadratic deviation to the middle arithmetic:
.
Also, the coefficient of variation is used as a characteristic of uniformity of the aggregate. If, then the oscilness is insignificant, if, the oscillating is moderate-mean, if, then the broadcast is significant, if, the aggregate is homogeneous.
Oscill coefficient:
.
Relative linear deviation:
.
Variation of features is due to various factors, some of these factors can be allocated if the statistical set is divided into groups according to any sign. Then, along with the study of the variation of the feature along the entire population as a whole, it becomes possible to study the variation for each of the components of its group, as well as between these groups. In the simplest case, when the aggregate is dissected to the group by one factor, the study of the variation is achieved by calculating and analyzing three types of dispersions: common, intergroup and intragroup.
Total dispersionmeasures the variation of the feature along the entire totality under the influence of all factors that caused this variation. It is equal to the average square of deviations of the individual value of the sign X from the total average value and can be calculated as a simple dispersion or suspended dispersion.
Intergroup dispersionit characterizes the systematic variation of an effective feature due to the influence of a sign-factor laid in the base of the grouping. It is equal to the average square of departure of group (private) averages from the total average:
 ,
,
where F is the number of units in the group.
INTERGRUPAP (Private) Dispersion reflects a random variation, i.e. Part of the variation caused by the influence of unaccounted factors and independent of the sign-factor laid in the base grouping. It is equal to the average square of deviations of the individual values \u200b\u200bof the feature inside the group x from the middle arithmetic of this group X i (group mode) and can be calculated as a simple variance
or as a suspended dispersion.
Based on the intragroup dispersion for each group, i.e. Based on, it is possible to determine the total middle of the intragroup dispersions :.
According to rule of addition dispersions The total dispersion is equal to the sum of the middle of the intragroup and intergroup dispersions:
.
Using the rule of addition of dispersions, it is always possible to determine the third - unknown dispersion in two known dispersions. The larger the proportion of intergroup dispersion in the overall dispersion, the stronger the influence of the grouping feature on the studied sign.
Therefore, in statistical analysis is widely used empirical determination coefficient - An indicator that is a fraction of an intergroup dispersion in a general dispersion of an effective feature and characterizing the effect of a grouping trait on the formation of a common variation:
.
The empirical coefficient of determination shows the proportion of the variation of the productive w.under the influence of a factor h. (The rest of the total variation is due to the variation of other factors). In the absence of communication, the empirical determination coefficient is zero, and with a functional connection - one.
Empirical correlation - This is a square root from the empirical coefficient of determination :.
It shows the tightness of the relationship between grouping and effective signs. Empirical correlation relationship can take values \u200b\u200bfrom 0 to 1. If there is no connection, then the correlation ratio is zero, i.e. All group averages will be among themselves, the intergroup variation will not be. So, the grouping feature does not affect the formation of a common variation. If the connection is functional, the correlation relationship will be equal to one. In this case, the dispersion of group average is equal to the total dispersion, i.e. The intragroup variation will not be. This means that the grouping feature is entirely determined by the variation of the studied performance. The value of the correlation rate is closer to one, the more closer, closer to the functionality of the relationship between the signs.
Task 2. Relative indicators
Option 10. The following population data for 1999 and territory in two countries are available:
|
Country |
Population population (million people) |
Territory (km 2) |
|
Moldova |
64.6 |
|
|
Ukraine |
49.7 |
603.7 |
Determine:
The average annual growth rate.
Decision
The absolute increase characterizes the size of increasing or decreased by the phenomenon under a certain period of time. It is defined as a difference between this level and the previous (chain) or initial (basic).
For dynamic row
 consisting of n + 1. levels, the absolute increase is determined in this way:
consisting of n + 1. levels, the absolute increase is determined in this way: chain, where is the current level of the row, the level preceding.
the basic, where - the current level of the row, is the initial level of the series.
 (MILL.)
(MILL.) (MILL.)
(MILL.) (MILL.)
(MILL.) (MILL.)
(MILL.) (MILL.)
(MILL.) (MILL.)
(MILL.) (MILL.)
(MILL.) (MILL.)
(MILL.)The average absolute increase is calculated by the formula
 ,
,where is the final level of the row.
That is, the average annual population of Ukraine for this period of time decreased by an average of 0.4 million people per year.
The growth rate is the ratio of this phenomenon level to the previous (chain) or an initial (basic) level, expressed as a percentage. Growth rates are calculated by formulas:
chain.
basis.








The growth rate is called the absolute growth ratio to the previous (chain) or initial (basic) level, expressed as a percentage. Growth rates are calculated by formulas:
chain
 .
.
Population density on both countries.
The relative comparison indicator is due to the population.
Decision
The population density is calculated as a relative rate of intensity (opi), which characterizes the degree of distribution or the level of development of a phenomenon in a certain environment. It is calculated as the ratio of the indicator characterizing the phenomenon, to the indicator that characterizes the spreading medium.
OPI Moldova \u003d ![]() chel / km 2. Those. Moldova population density 31.15 people per 1 km 2.
chel / km 2. Those. Moldova population density 31.15 people per 1 km 2.
OPI Azerbaijan \u003d. ![]() chel / km 2. Those. The density of the population of Ukraine is 82.33 people per 1 km 2.
chel / km 2. Those. The density of the population of Ukraine is 82.33 people per 1 km 2.
OPS \u003d.  . Those. The territory of Ukraine is 20.708 times (or 1970%) more than the territory of Moldova.
. Those. The territory of Ukraine is 20.708 times (or 1970%) more than the territory of Moldova.
Task 3. Middle Indicators
Option 10. There are the following data on the distribution of the number of unemployed women registered by employment services, by age groups at the end of 1999 (th.):
|
Age |
less than 20. |
20-25 |
25-30 |
30-35 |
35-40 |
40-45 |
45-50 |
50 and older |
|
The number of unemployed |
12,7 |
11,3 |
Find the average age value of the registered unemployed.
Decision
In order to calculate the average arithmetic interval series, you must first go to a conditional discrete row from the average interval values. If there are intervals without specifying the lower boundary or the upper boundary (50 and older), then the corresponding value is set in such a way that a row with isometric intervals. In this case, the conditional discrete row has the form:
|
Age |
17,5 |
22,5 |
27,5 |
32,5 |
37,5 |
42,5 |
47,5 |
52,5 |
|
Population size |
12,7 |
11,3 |
,
where x I. – i.the meaning of the sign
n I. - Frequency x I., k. - the number of different signs in the aggregate.
 . Those. The average value of the age is 35.0 years.
. Those. The average value of the age is 35.0 years.
Task 4. Rows of speakers
Option 10. There are the following data on the dynamics of the average annual population of Ukraine (million people):
|
Years |
1995 |
1996 |
1997 |
1998 |
1999 |
|
Population size |
51,3 |
50,9 |
50,4 |
50,0 |
49,7 |
Determine:
Absolute gains (chains and basic).
Middle absolute increase.
Growth rates (chain and basic).
Growth rates (chains and basic).
Absolute value of 1% increase.
Information about the mean levels of the generals under study is usually insufficient for deep analysis of the underlying process or phenomenon. It is necessary to take into account the scatter or the variation of the individual values \u200b\u200bof the studied attribute, which is an important characteristic of the aggregate under study.
The variation is called the variance, variety, the variability of the sign value in units of the aggregate.
The variation is generated by a complex of conditions acting on the totality and its units. For example, a variation of estimates on the exam in high school is generated, in particular, by various abilities of students, unequal times spent by them for independent work, the difference in social and living conditions. It is the variation and predetermines the need for statistics. If all students received the same estimates or, for example, families had the same income, then the need for a statistical study would have fallen.
Measuring variations makes it possible to assess the degree of impact on this feature of other varying signs, establish which factors and to what extent affect the mortality of the population, the financial situation of enterprises, the yield of grain crops, etc. The determination of the variation is necessary when organizing selective observation, the construction of statistical models, the development of materials of expert surveys and in many other cases.
How does statistics give a quantitative evaluation of the extent of the characteristics in the aggregate, measures the variation? For this purpose, such indicators are used as variation variation, the average linear deviation, dispersion, the average quadratic deviation, the variation coefficient. All these indicators are widely used in socio-economic statistics, so consider their essential and logical basis.
Indicators of variation and methods for their calculation
Variation indicators are divided into two groups: absolute and relative.
TO absolute indicators the variation variation, the average linear deviation, dispersion and the average quadratic deviation.
Number relative indicators of variation the coefficient of variation, relative linear deviation, etc.
Variation variation
This indicator is calculated as the difference between the largest and the smallest values \u200b\u200bof the variation characteristic:
It shows how large the difference between the units of aggregate having the smallest (A "T (P) and the greatest value of the sign (HTC). For example, the difference between the maximum and minimal pension of different groups of the population, the income level of various categories of working or developing organizations from Working specific specialty or qualifications.
Range is an important characteristic of the variation, it gives the first overall idea of \u200b\u200bthe difference in units inside the totality. This indicator is expressed in those named numbers in which the signs are expressed.
The peculiarity of the variation is that it depends only on the two extreme signs of the feature. For this reason, it is advisable to apply it in cases where the minimum, or the maximum option, i.e. When the variation is a big semantic value. For example, they define the limits in which the dimensions of certain parts or other parameters can vary; It is used when evaluating various risks. Another side of this feature is that at the magnitude of the variation in the variation, an accident has a great influence. Since only two signs of the feature are taken from the statistical series, and extreme in the row, on the discharge of these values, the causes of a random nature can be influenced, then the variation variation may be dependent on the causes of a random nature.
With a marked feature, the fact that the index of the variation is not taken into account frequencies in the variational series of distribution.
According to the selective examination, depositors were grouping in terms of deposit in Sberbank of the city:
Determine:
1) variation variation;
2) the average deposit size;
3) the average linear deviation;
4) dispersion;
5) secondary quadratic deviation;
6) Coefficient of variation of deposits.
Decision:
This distribution range contains open intervals. In such rows, the magnitude of the interval of the first group is conditionally taken equal to the value of the subsequent interval, and the magnitude of the interval of the last group is equal to the magnitude of the interval of the previous one.
The magnitude of the second group of the group is 200, therefore, the amount of the first group is also equal to 200. The size of the interval of the penultimate group is 200, which means the last interval will have a value equal to 200.
1) We will define the scope of the variation as a difference between the greatest and the smallest sign of the feature:
The scope of the variation of the contribution size is 1000 rubles.
2) The average deposit size is determined by the formula of the average arithmetic weighted.
Previously determine the discrete value of the trait in each interval. To do this, according to the middle arithmetic formula, we will find the middle of the intervals.
The average value of the first interval will be:

second - 500, etc.
Let us enter the results of the calculations in the table:
| Deposit size, rub. | The number of depositors, f | Middle interval, x | xF. |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| TOTAL | 400 | - | 312000 |
The average deposit in the Sberbank of the city will be 780 rubles:
3) The average linear deviation is the average arithmetic of absolute deviations of individual values \u200b\u200bof the feature of the total average:

The procedure for calculating the average deflection lineongo in the interval range of the distribution is as follows:
1. The average arithmetic weighted is calculated, as shown in paragraph 2).
2. The absolute deviations are determined from the average:
3. The deviations obtained are multiplied by frequencies:
4. There is a sum of weighted deviations without taking into account the sign:
5. The amount of weighted deviations is divided into frequencies:
It is convenient to use the calculated data table:
| Deposit size, rub. | The number of depositors, f | Middle interval, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| TOTAL | 400 | - | - | - | 81280 |

The average linear deviation of the contribution of Sberbank's customers is 203.2 rubles.
4) Dispersion is the average arithmetic squares of deviations of each character value from the middle arithmetic.
The calculation of the dispersion in the interval distribution rows is made by the formula:

The procedure for calculating the dispersion in this case is the following:
1. Determine the average arithmetic weighted, as shown in paragraph 2).
2. Find deviations option from the average:
3. Early the deviations of each options from the average:
4. Multiple the squares for weight deviations (frequencies):
![]()
5. Slimming the works obtained:
![]()
6. The resulting amount is divided into summation (frequencies):

Calculations to be issued in the table:
| Deposit size, rub. | The number of depositors, f | Middle interval, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| TOTAL | 400 | - | - | - | 23040000 |
Variation - This is a change (oscillating) of the signs of the attribute within the largest set when switching from one object (group of objects), or from one occasion to another. Absolute and relative indicators of variation characterizing the amounts of varying values \u200b\u200ballow, in particular, measure the degree of communication and interdependence between the signs, determine the degree of homogeneity of the totality, typical and sustainability of the average, determine the magnitude of the error of selective observation, to statistically assess the law of the distribution of the totality, etc. .
In this topic, it is necessary to understand the essence (meaning), the appointment and methods for calculating each indicator of the variation considered to know the theory of statistics: variations, the average linear deviation, the average square of deviations (dispersion), the average quadratic deviation, the relative coefficients of the variation (oscillation coefficient, coefficient medium linear deviation, variation coefficient).
Variation variation (R.) it is a difference between the maximum (x max) and minimal (x min) values \u200b\u200bof the symptoms in the aggregate (in a number of distribution):
R \u003d x Max - x min. (5.1)
The measure of other variation indicators is the difference is not between the extreme values \u200b\u200bof the feature, but the average difference between each sign and the average value of these signs. The difference between the individual value of the trait and medium is called deviation.
Medium linear deviation The following formulas are calculated:
according to individual (non-major) data
 ;
(5.2)
;
(5.2)
by variational series (grouped data)
 .
(5.3)
.
(5.3)
Since the algebraic sum of deviations of individual values \u200b\u200bof the feature from the average (according to zero property) is always zero, then when calculating the average linear deviation, the arithmetic amount of deviations taken by module is used, i.e.  .
.
The average linear deviation has the same dimension as the feature for which it is calculated.
Dispersion and average quadratic deviation. The average linear deviation is relatively rarely used to evaluate the variation of the feature. Therefore, the dispersion ( 2) is usually calculated and the average quadratic deviation (). These indicators are applied not only to estimate the variation of the feature, but also to measure the relationship between them, to assess the value of the error of the sample observation and other purposes.
Dispersion feature Calculated by formulas:
according to primary data
 ; (5.4)
; (5.4)
by variational rows
 . (5.5)
. (5.5)
Average quadratic deviation It is a root square from the dispersion:
according to primary data
 ; (5.6)
; (5.6)
by variational rows
 . (5.7)
. (5.7)
The average quadratic deviation is as well as the average linear deviation, has the same dimension as the original sign itself.
The dispersion can be determined and as a difference between the middle square of the variants and the square of their average value, i.e.  .
(5.8)
.
(5.8)
In this case, according to primary data, the dispersion is equal to:
 (5.9)
(5.9)
In relation to the grouped data, the calculation of the dispersion in this method is submitted in this form:
 . (5.10)
. (5.10)
For rows of distribution at equal intervals, the dispersion value can be calculated using the method of conditional moments, i.e.
 , (5.11)
, (5.11)
where  - the first conditional moment; (5.12)
- the first conditional moment; (5.12)
 - The second conditional moment. (5.13)
- The second conditional moment. (5.13)
The average quadratic deviation by the method of conditional moments is determined by the formula:
 (5.14)
(5.14)
Converting the expression of the calculation of the dispersion by the method of conditional moments, we obtain the formula of the form:  (5.15)
(5.15)
Based on the same source data, we obtain the same variance value.
Relative parameters of variations are calculated as a ratio of a number of absolute parameters of variation to their middle arithmetic and are expressed as a percentage:
oscillation coefficient -  ; (5.16)
; (5.16)
relative linear deflection coefficient -  ; (5.17)
; (5.17)
the coefficient of variation -  . (5.18)
. (5.18)
Task 1.. Consider the methods for calculating the indicators of variation based on the data Table. 5.1.
Table 5.1.Source data for calculating variation indicators
|
The cost of time for the production of mines |
Number of details, pcs. (f) |
Midstand interval (x) |
|
|
|
|
|
|
|
|||







 ; K \u003d 2.
; K \u003d 2.
The given range of distribution ranked, so it is easy to find the minimum characteristic value, it is 8 minutes. (10 - 2), and the maximum, equal to 18 minutes. (16 + 2). So, the scope of the characterization of the sign in this row will be 10 minutes., I.e.
R \u003d x max - x min \u003d 18 - 8 \u003d 10 min.
We calculate the average linear deviation. First of all, it is necessary to calculate the average value  . All calculations will be conducted in tabular form (Table 5.1.), Distinguishing for each computing operation of the Count in the table.
. All calculations will be conducted in tabular form (Table 5.1.), Distinguishing for each computing operation of the Count in the table.
Since the initial data is presented by a number of distribution,
 min.
min.
 min.
min.
We show ways to calculate the dispersion:
a) in the usual way (by definition):
 ;
;
b) as a difference between the middle square and the square of the average size:

To determine the magnitude of the dispersion for this formula, it is necessary to calculate the average square of the feature options by the formula:
 ;
;
2 \u003d 178,6 - (13.2) 2 \u003d 4.36;
c) by the method of conditional moments:
 ;
;
 ;
;
d) based on the transformation of the formula for calculating the dispersion by the method of conditional moments we have:
Dispersion - a number of distracted, not having units of measurement.
The average quadratic deviation is calculated by extracting square root from the dispersion:
 min.
min.
By the method of conditional moments, the magnitude of the average quadratic deviation is determined as follows:
We calculate the relative indicators of the variation:
 %;
%;
 %;
%;
 %.
%.
The main relative parameter of the variation is the variation coefficient (V). It is used for a comparative assessment of the measure of signs expressed in various units of measurement.
Along with the variation of quantitative signs, a variation of high-quality signs may also be observed (in particular alternative variability of high-quality signs). In this case, each unit of studied aggregate or has some property, or not (for example, every adult person either works or not). The presence of a sign in units of aggregate is denoted by 1, and the absence of -0; The share of the units of the aggregate, which have a studied sign, denote P, and not possessing them - q. The dispersion of an alternative feature is determined by the formula:
 ; (5.19)
; (5.19)
p + Q \u003d 1 (5.20)
If, for example, the proportion of the university received to 30%, and not received - 70%, then the dispersion is 0.21 (0.3 · 0.7). The maximum value of the product Pq is 0.25 (provided that one half of units has this feature, and the other half does not have: (0,5 · 0.5 \u003d 0.25).
Method of decomposition of general dispersion. To assess the influence of various factors that determine the variance of individual signs of the feature, we will use the decomposition of a general dispersion to the components: on the so-called group dispersion and the average of intragroup dispersions:
 , (5.21)
, (5.21)
where  - General dispersion, which characterizes the characterization of the feature as a result of the influence of all factors that determine individual differences in the units of the aggregate.
- General dispersion, which characterizes the characterization of the feature as a result of the influence of all factors that determine individual differences in the units of the aggregate.
The variation of the feature caused by the influence of the factor based on the grouping characterizes the intergroup dispersion 2, which is a measure of varying medium in groups  around the total average and calculated by the formula:
around the total average and calculated by the formula:
 , (5.22)
, (5.22)
where N j is the number of units of aggregate in each group;
j is the group sequence number.
The variation of the feature caused by the influence of all other factors besides the grouping (factor) characterizes in each group of intragroup dispersion:
 , (5.23)
, (5.23)
where i is the sequence number X and F within each group.
By the aggregate as a whole, the average of the intragroup dispersions is determined by the formula:
 (5.24)
(5.24)
The relationship of intergroup dispersion 2 to the total  give the coefficient of determination:
give the coefficient of determination:
 (5.25)
(5.25)
which characterizes the proportion of the variation of an effective feature caused by the variation of a factor-based characteristic of the grouping.
The indicator obtained as the root square from the determination coefficient is called the coefficient of an empirical correlation ratio, i.e.:
 (5.26)
(5.26)
It characterizes the tightness of the relationship between the effective and factor (based on the basis of the grouping) signs. The numerical value of the coefficient of the empirical correlation relationship has two signs: . In solving the question of whether it should be taken with which it should be taken, it is necessary to keep in mind: if the variation of factor and productive features is synchronously in the same direction (increases or decreases), the correlation relationship is taken with a plus sign; If the change in these signs is in opposite directions, it is taken with a minus sign.
To calculate group and intergroup dispersions, you can apply any of the methods for calculating the mid-square deviations.
Task 2. Calculate all the named dispersions on the source data of the table. 5.2.
Table 5.2. Distribution of the seed area of \u200b\u200bwinter wheat on yield
|
Plot number |
Yield, c / ha |
Sowing Square, ha | |||
We calculate the average yield of winter wheat on all areas (total average):
 c / ha.
c / ha.
General dispersion We will find by the formula:

In c. 6 table. 5.2. Calculate the values \u200b\u200bfor calculating the mid-square feature options:
 .
.
Find a general dispersion:
The yield depends on many factors (the quality of the soil, the size of the introduction of organic and mineral fertilizers, the quality of seeds, the timing of sowing, sowing, etc.) The overall dispersion in this case measures the amount of yields due to all factors.
Task 3. We will break the set of areas into two groups: I Group - Sowing Squares, on which organic fertilizers were not introduced; II - the squares on which they contributed. To the first group, we will draw the sections 1-4, and to the second - 4-8. According to these groups, we will calculate the rest of the dispersions you need using already produced in Table. 5.2. Calculations.
Table 5.3. Estimated data for calculating intergroup and group dispersions
|
Plot number |
Yield, c / ha) |
Sourish area, ha (f) |
Plot number |
Yield, c / ha) |
Sourish area, ha (f) | ||||||
Determine:
|
for group I: |
for group II: |
|
a) group average |
a) group average |
|
|
|
|
b) the middle square of the feature options |
|
|
|
|
|
c) group dispersion |
c) group dispersion |
 c / ha;
c / ha; c / ha;
c / ha; ;
; ;
;We define the average of group dispersions:
 .
.
We find intergroup dispersion:
The average of group dispersions measures the transmission of the characteristic due to all other factors, except for the basis of the grouping (separation into groups), and the intergroup - at the expense of this particular factor. The sum of these dispersions should give a general dispersion, namely:
The relationship of intergroup dispersion to the general in our example will give the following value of the determination coefficient:
 , or 71.8%,
, or 71.8%,
i.e., the variation of the yield of winter wheat by 71.8% depends on the variation of the size of the application of organic fertilizers. The remaining 28.2% variations of yield depends on the influence of all other factors, except for the size of the application of organic fertilizers.
The coefficient of empirical correlation is:
 .
.
This suggests that the introduction of organic fertilizers has a very significant impact on the yield.