The dispersion is characterized. Absolute Variation Rates
This page describes a standard example of finding the variance, you can also look at other tasks for finding it
Example 1. Determination of group, average of group, between-group and total variance
Example 2. Finding the variance and coefficient of variation in a grouping table
Example 3. Finding the variance in discrete series
Example 4. We have the following data for a group of 20 correspondence students. It is necessary to build an interval series of the feature distribution, calculate the mean value of the feature and study its variance
Let's build an interval grouping. Let's determine the range of the interval by the formula:
![]()
where X max– maximum value grouping sign;
X min is the minimum value of the grouping feature;
n is the number of intervals:
We accept n=5. The step is: h \u003d (192 - 159) / 5 \u003d 6.6
Let's make an interval grouping

For further calculations, we will build an auxiliary table:

X "i - the middle of the interval. (for example, the middle of the interval 159 - 165.6 \u003d 162.3)
The average growth of students is determined by the formula of the arithmetic weighted average:

We determine the dispersion by the formula:
The formula can be converted like this:

From this formula it follows that the variance is the difference between the mean of the squares of the options and the square and the mean.
Dispersion in variation series With at equal intervals according to the method of moments can be calculated in the following way using the second property of the dispersion (dividing all options by the value of the interval). Definition of variance, calculated by the method of moments, according to the following formula is less time consuming:

where i is the value of the interval;
A - conditional zero, which is convenient to use the middle of the interval with the highest frequency;
m1 is the square of the moment of the first order;
m2 - moment of the second order
Feature variance (if in the statistical population the attribute changes in such a way that there are only two mutually exclusive options, then such variability is called alternative) can be calculated by the formula:

Substituting in this formula dispersion q \u003d 1- p, we get:

Types of dispersion
Total variance measures the variation of a trait over the entire population as a whole under the influence of all the factors that cause this variation. It is equal to the mean square of the deviations of the individual values of the attribute x from the total average value x and can be defined as simple variance or weighted variance.
Intragroup variance characterizes random variation, i.e. part of the variation, which is due to the influence of unaccounted for factors and does not depend on the sign-factor underlying the grouping. Such a variance is equal to the mean square of the deviations of the individual values of a feature within the X group from the arithmetic mean of the group and can be calculated as a simple variance or as a weighted variance.
In this way, within-group variance measures variation of a trait within a group and is determined by the formula:

where xi - group average;
ni is the number of units in the group.
For example, intra-group variances, which must be determined in the problem of studying the influence of workers' qualifications on the level of labor productivity in the shop, show variations in output in each group, caused by all possible factors ( technical condition equipment, availability of tools and materials, age of workers, labor intensity, etc.), except for differences in the qualification category (within the group, all workers have the same qualifications).
Types of dispersions:
Total variance characterizes the variation of the trait of the entire population under the influence of all those factors that caused this variation. This value is determined by the formula
where is the general arithmetic mean of the entire study population.
Average within-group variance indicates a random variation that may arise under the influence of any unaccounted for factors and which does not depend on the characteristic factor underlying the grouping. This variance is calculated as follows: first, the variances for individual groups are calculated (), then the average within-group variance is calculated:
 where n i is the number of units in the group
where n i is the number of units in the group
Intergroup variance(dispersion of group means) characterizes systematic variation, i.e. differences in the value of the trait under study, arising under the influence of the trait-factor, which is the basis of the grouping.

where is the average value for a separate group.
All three types of dispersion are interconnected: total variance is equal to the sum of the average intragroup variance and intergroup variance:
![]()
Properties:
25 Relative rates of variation
|
Oscillation factor |
|
|
Relative linear deviation |
|
|
The coefficient of variation |
|
Coef. Osc. O reflects the relative fluctuation of the extreme values of the attribute around the average. Rel. lin. off. characterizes the share of the average value of the sign of absolute deviations from medium size. Coef. Variation is the most common measure of variation used to assess the typicality of averages.
In statistics, populations with a coefficient of variation greater than 30–35% are considered to be heterogeneous.
Regularity of distribution series. distribution moments. Distribution form indicators
In variational series, there is a relationship between frequencies and values of a variable attribute: with an increase in the attribute, the frequency value first increases to a certain limit, and then decreases. Such changes are called distribution patterns.
The form of distribution is studied using indicators of asymmetry and kurtosis. When calculating these indicators, distribution moments are used.
The moment of the k-th order is the average of the k-th degrees of deviations of the variants of the attribute values from some constant value. The order of the moment is determined by the value k. When analyzing variational series, they confine themselves to calculating the moments of the first four orders. When calculating moments, frequencies or frequencies can be used as weights. Depending on the choice of a constant value, there are initial, conditional and central moments.
Distribution form indicators:
Asymmetry(As) indicator characterizing the degree of distribution asymmetry .

Therefore, with (left-handed) negative skewness  . With (right-sided) positive asymmetry
. With (right-sided) positive asymmetry  .
.
Central moments can be used to calculate asymmetry. Then:
 ,
,
where μ 3 is the central moment of the third order.
- kurtosis (E To ) characterizes the steepness of the graph of the function in comparison with the normal distribution with the same strength of variation:
 ,
,
where μ 4 is the central moment of the 4th order.
For a normal distribution (Gaussian distribution), the distribution function has the following form:


Expectation - standard deviation
The normal distribution is symmetrical and is characterized by the following relationship: Xav=Me=Mo
The kurtosis of the normal distribution is 3 and the skewness is 0.
The normal distribution curve is a polygon (symmetrical bell-shaped straight line)
Types of dispersions. Rule for adding variances. The essence of the empirical coefficient of determination.
If the initial population is divided into groups according to some essential feature, then the following types of dispersions are calculated:
Total variance of the original population:
where is the total average value of the original population; f is the frequency of the original population. The total variance characterizes the deviation of the individual values of the attribute from the total average value of the original population.
Intragroup variances:
where j is the number of the group; is the average value in each j-th group; is the frequency of the j-th group. Intragroup variances characterize the deviation of the individual value of a trait in each group from the group average. From all intra-group dispersions, the average is calculated by the formula:, where is the number of units in each j-th group.
Intergroup variance:
Intergroup dispersion characterizes the deviation of group averages from the total average of the original population.
Variance addition rule is that the total variance of the original population should be equal to the sum of the intergroup and the average of the intragroup variances:
Empirical coefficient of determination shows the proportion of the variation of the studied trait, due to the variation of the grouping trait, and is calculated by the formula:
Method of reference from conditional zero (method of moments) for calculating the mean and variance
The calculation of the dispersion by the method of moments is based on the use of the formula and 3 and 4 properties of the dispersion.
(3. If all the values of the attribute (options) are increased (decreased) by some constant number A, then the variance of the new population will not change.
4. If all the values of the attribute (options) are increased (multiplied) by K times, where K is a constant number, then the variance of the new population will increase (decrease) by K 2 times.)
We obtain the formula for calculating the variance in variational series with equal intervals by the method of moments:

A - conditional zero, equal to the option with the maximum frequency (middle of the interval with the maximum frequency)
The calculation of the mean by the method of moments is also based on the use of the properties of the mean.
![]()
The concept of selective observation. Stages of the study of economic phenomena by a selective method
A sample is an observation in which not all units of the original population are examined and studied, but only a part of the units, while the result of the survey of a part of the population is extended to the entire original population. The set from which the selection of units for further examination and study is called general and all indicators characterizing this set are called general.
Possible limits of deviations of the sample mean from the general mean are called sampling error.
The set of selected units is called selective and all indicators characterizing this set are called selective.
Selective research includes the following steps:
Characteristics of the object of study (mass economic phenomena). If the general population is small, then sampling is not recommended, a continuous study is necessary;
Sample size calculation. It is important to determine the optimal volume that will allow, at the lowest cost, to obtain a sampling error within the acceptable range;
Carrying out the selection of units of observation, taking into account the requirements of randomness, proportionality.
Evidence of representativeness based on an estimate of sampling error. For a random sample, the error is calculated using formulas. For the target sample, representativeness is assessed using qualitative methods (comparison, experiment);
Sample analysis. If the formed sample meets the requirements of representativeness, then it is analyzed using analytical indicators (average, relative, etc.)
Probability theory is a special branch of mathematics that is studied only by students of higher educational institutions. Do you love calculations and formulas? You are not afraid of the prospects of acquaintance with the normal distribution, ensemble entropy, mathematical expectation and discrete variance random variable? Then this subject will be of great interest to you. Let's get acquainted with some of the most important basic concepts of this section of science.
Let's remember the basics
Even if you remember the simplest concepts of probability theory, do not neglect the first paragraphs of the article. The fact is that without a clear understanding of the basics, you will not be able to work with the formulas discussed below.
So, there is some random event, some experiment. As a result of the actions performed, we can get several outcomes - some of them are more common, others less common. The probability of an event is the ratio of the number of actually obtained outcomes of one type to the total number of possible ones. Only knowing the classical definition of this concept, you can begin to study mathematical expectation and dispersions of continuous random variables.
Average
Back in school, in mathematics lessons, you started working with the arithmetic mean. This concept is widely used in probability theory, and therefore it cannot be ignored. The main thing for us this moment is that we will encounter it in the formulas for the mathematical expectation and variance of a random variable.

We have a sequence of numbers and want to find the arithmetic mean. All that is required of us is to sum everything available and divide by the number of elements in the sequence. Let we have numbers from 1 to 9. The sum of the elements will be 45, and we will divide this value by 9. Answer: - 5.
Dispersion
talking scientific language, variance is the average square of the deviations of the obtained feature values from the arithmetic mean. One is denoted by a capital Latin letter D. What is needed to calculate it? For each element of the sequence, we calculate the difference between the available number and the arithmetic mean and square it. There will be exactly as many values as there can be outcomes for the event we are considering. Next, we summarize everything received and divide by the number of elements in the sequence. If we have five possible outcomes, then divide by five.

The variance also has properties that you need to remember in order to apply it when solving problems. For example, if the random variable is increased by X times, the variance increases by X times the square (i.e., X*X). It is never less than zero and does not depend on shifting values by an equal value up or down. Also, for independent trials, the variance of the sum is equal to the sum of the variances.
Now we definitely need to consider examples of the variance of a discrete random variable and the mathematical expectation.
Let's say we run 21 experiments and get 7 different outcomes. We observed each of them, respectively, 1,2,2,3,4,4 and 5 times. What will be the variance?
First, we calculate the arithmetic mean: the sum of the elements, of course, is 21. We divide it by 7, getting 3. Now we subtract 3 from each number in the original sequence, square each value, and add the results together. It turns out 12. Now it remains for us to divide the number by the number of elements, and, it would seem, that's all. But there is a catch! Let's discuss it.
Dependence on the number of experiments
It turns out that when calculating the variance, the denominator can be one of two numbers: either N or N-1. Here N is the number of experiments performed or the number of elements in the sequence (which is essentially the same thing). What does it depend on?

If the number of tests is measured in hundreds, then we must put N in the denominator. If in units, then N-1. The scientists decided to draw the border quite symbolically: today it runs along the number 30. If we conducted less than 30 experiments, then we will divide the amount by N-1, and if more, then by N.
Task
Let's go back to our example of solving the variance and expectation problem. We got an intermediate number of 12, which had to be divided by N or N-1. Since we conducted 21 experiments, which is less than 30, we will choose the second option. So the answer is: the variance is 12 / 2 = 2.
Expected value
Let's move on to the second concept, which we must consider in this article. The mathematical expectation is the result of adding all possible outcomes multiplied by the corresponding probabilities. It is important to understand that the resulting value, as well as the result of calculating the variance, is obtained only once for the whole task, no matter how many outcomes it considers.

The mathematical expectation formula is quite simple: we take the outcome, multiply it by its probability, add the same for the second, third result, etc. Everything related to this concept is easy to calculate. For example, the sum of mathematical expectations is equal to the mathematical expectation of the sum. The same is true for the work. Not every quantity in probability theory allows such simple operations to be performed. Let's take a task and calculate the value of two concepts we have studied at once. In addition, we were distracted by theory - it's time to practice.
One more example
We ran 50 trials and got 10 kinds of outcomes - numbers 0 to 9 - appearing in varying percentages. These are, respectively: 2%, 10%, 4%, 14%, 2%, 18%, 6%, 16%, 10%, 18%. Recall that to get the probabilities, you need to divide the percentage values by 100. Thus, we get 0.02; 0.1 etc. Let us present an example of solving the problem for the variance of a random variable and the mathematical expectation.
We calculate the arithmetic mean using the formula that we remember from elementary school: 50/10 = 5.
Now let's translate the probabilities into the number of outcomes "in pieces" to make it more convenient to count. We get 1, 5, 2, 7, 1, 9, 3, 8, 5 and 9. Subtract the arithmetic mean from each value obtained, after which we square each of the results obtained. See how to do this with the first element as an example: 1 - 5 = (-4). Further: (-4) * (-4) = 16. For other values, do these operations yourself. If you did everything right, then after adding everything you get 90.

Let's continue calculating the variance and mean by dividing 90 by N. Why do we choose N and not N-1? That's right, because the number of experiments performed exceeds 30. So: 90/10 = 9. We got the dispersion. If you get a different number, don't despair. Most likely, you made a banal error in the calculations. Double-check what you wrote, and for sure everything will fall into place.
Finally, let's recall the mathematical expectation formula. We will not give all the calculations, we will only write the answer with which you can check after completing all the required procedures. The expected value will be 5.48. We only recall how to carry out operations, using the example of the first elements: 0 * 0.02 + 1 * 0.1 ... and so on. As you can see, we simply multiply the value of the outcome by its probability.
Deviation
Another concept closely related to dispersion and mathematical expectation is the standard deviation. It is denoted either by the Latin letters sd, or by the Greek lowercase "sigma". This concept shows how, on average, values deviate from the central feature. To find its value, you need to calculate Square root from dispersion.

If you plot a normal distribution and want to see directly on it standard deviation, this can be done in several steps. Take half of the image to the left or right of the mode (central value), draw a perpendicular to the horizontal axis so that the areas of the resulting figures are equal. The value of the segment between the middle of the distribution and the resulting projection on the horizontal axis will be the standard deviation.
Software
As can be seen from the descriptions of the formulas and the examples presented, calculating the variance and mathematical expectation is not the easiest procedure from an arithmetic point of view. In order not to waste time, it makes sense to use the program used in higher educational institutions- it's called "R". It has functions that allow you to calculate values for many concepts from statistics and probability theory.
For example, you define a vector of values. This is done as follows: vector<-c(1,5,2…). Теперь, когда вам потребуется посчитать какие-либо значения для этого вектора, вы пишете функцию и задаете его в качестве аргумента. Для нахождения дисперсии вам нужно будет использовать функцию var. Пример её использования: var(vector). Далее вы просто нажимаете «ввод» и получаете результат.
Finally
Dispersion and mathematical expectation are without which it is difficult to calculate anything in the future. In the main course of lectures at universities, they are considered already in the first months of studying the subject. It is precisely because of the lack of understanding of these simple concepts and the inability to calculate them that many students immediately begin to fall behind in the program and later receive poor marks in the session, which deprives them of scholarships.
Practice at least one week for half an hour a day, solving tasks similar to those presented in this article. Then, on any probability theory test, you will cope with examples without extraneous tips and cheat sheets.
Along with the study of the variation of a trait throughout the entire population as a whole, it is often necessary to trace the quantitative changes in the trait in groups into which the population is divided, as well as between groups. This study of variation is achieved by calculating and analyzing various kinds of variance.
Distinguish between total, intergroup and intragroup dispersion.
Total variance σ 2 measures the variation of a trait over the entire population under the influence of all the factors that caused this variation, .
Intergroup variance (δ) characterizes systematic variation, i.e. differences in the magnitude of the trait under study, arising under the influence of the trait-factor underlying the grouping. It is calculated by the formula: 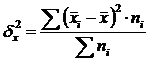 .
.
Within-group variance (σ) reflects random variation, i.e. part of the variation that occurs under the influence of unaccounted for factors and does not depend on the trait-factor underlying the grouping. It is calculated by the formula: 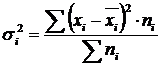 .
.
Average of within-group variances:  .
.
There is a law linking 3 types of dispersion. The total variance is equal to the sum of the average of the intragroup and intergroup variances: ![]() .
.
This ratio is called variance addition rule.
In the analysis, a measure is widely used, which is the proportion of between-group variance in the total variance. It bears the name empirical coefficient of determination (η 2): .
The square root of the empirical coefficient of determination is called empirical correlation ratio (η):
 .
.
It characterizes the influence of the attribute underlying the grouping on the variation of the resulting attribute. The empirical correlation ratio varies from 0 to 1.
We will show its practical use in the following example (Table 1).
Example #1. Table 1 - Labor productivity of two groups of workers of one of the workshops of NPO "Cyclone"
Calculate the total and group averages and variances:
The initial data for calculating the average of the intragroup and intergroup dispersion are presented in Table. 2.
table 2
Calculation and δ 2 for two groups of workers.
|
Worker groups | Number of workers, pers. | Average, det./shift. | Dispersion |
| Passed technical training | 5 | 95 | 42,0 |
| Not technically trained | 5 | 81 | 231,2 |
| All workers | 10 | 88 | 185,6 |
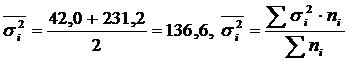 .
.
Intergroup variance
Total variance:
Thus, the empirical correlation ratio: .
Along with the variation of quantitative traits, a variation of qualitative traits can also be observed. This study of variation is achieved by calculating the following types of variances:
The intra-group variance of the share is determined by the formula
where n i– the number of units in separate groups.The proportion of the studied trait in the entire population, which is determined by the formula:
The three types of dispersion are related to each other as follows:
This ratio of variances is called the feature share variance addition theorem.
Dispersion is a measure of dispersion that describes the relative deviation between data values and the mean. It is the most commonly used measure of dispersion in statistics, calculated by summing, squared, the deviation of each data value from the mean. The formula for calculating the variance is shown below:
![]()
s 2 - sample variance;
x cf is the mean value of the sample;
n — sample size (number of data values),
(x i – x cf) is the deviation from the mean value for each value of the data set.
To better understand the formula, let's look at an example. I don't really like cooking, so I rarely do it. However, in order not to die of hunger, from time to time I have to go to the stove to implement the plan to saturate my body with proteins, fats and carbohydrates. The data set below shows how many times Renat cooks food each month:
The first step in calculating the variance is to determine the sample mean, which in our example is 7.8 times a month. The remaining calculations can be facilitated with the help of the following table.

The final phase of calculating the variance looks like this:
![]()
For those who like to do all the calculations in one go, the equation will look like this:
Using the raw count method (cooking example)
There is a more efficient way to calculate the variance, known as the "raw counting" method. Although at first glance the equation may seem quite cumbersome, in fact it is not so scary. You can verify this, and then decide which method you like best.

is the sum of each data value after squaring,
is the square of the sum of all data values.
Don't lose your mind right now. Let's put it all in the form of a table, and then you will see that there are fewer calculations here than in the previous example.


As you can see, the result is the same as when using the previous method. The advantages of this method become apparent as the sample size (n) grows.
Calculating variance in Excel
As you probably already guessed, Excel has a formula that allows you to calculate the variance. Moreover, starting from Excel 2010, you can find 4 varieties of the dispersion formula:
1) VAR.V - Returns the variance of the sample. Boolean values and text are ignored.
2) VAR.G - Returns the population variance. Boolean values and text are ignored.
3) VASP - Returns the sample variance, taking into account boolean and text values.
4) VARP - Returns the variance of the population, taking into account logical and text values.
First, let's look at the difference between a sample and a population. The purpose of descriptive statistics is to summarize or display data in such a way as to quickly get a big picture, so to speak, an overview. Statistical inference allows you to make inferences about a population based on a sample of data from this population. The population represents all possible outcomes or measurements that are of interest to us. A sample is a subset of a population.
For example, we are interested in the totality of a group of students from one of the Russian universities and we need to determine the average score of the group. We can calculate the average performance of students, and then the resulting figure will be a parameter, since the whole population will be involved in our calculations. However, if we want to calculate the GPA of all students in our country, then this group will be our sample.
The difference in the formula for calculating the variance between the sample and the population is in the denominator. Where for the sample it will be equal to (n-1), and for the general population only n.
Now let's deal with the functions of calculating the variance with endings A, in the description of which it is said that the calculation takes into account text and logical values. In this case, when calculating the variance of a specific data set where non-numeric values occur, Excel will interpret text and false booleans as 0, and true booleans as 1.
So, if you have an array of data, it will not be difficult to calculate its variance using one of the Excel functions listed above.


