Dispersion icon. Calculation of group, intergroup and total variance (according to the rule of addition of variances)
Where σ 2 j is the intragroup variance of the j -th group.
For ungrouped data residual variance Is a measure of the approximation accuracy, i.e. approximation of the regression line to the original data: 
where y (t) is the forecast according to the trend equation; y t is the initial series of dynamics; n is the number of points; p is the number of coefficients of the regression equation (the number of explanatory variables).
In this example, it is called unbiased variance estimate.
Example # 1. The distribution of workers of three enterprises of one association according to tariff categories is characterized by the following data:
| Worker wage rate | The number of workers at the enterprise | ||
| enterprise 1 | enterprise 2 | enterprise 3 | |
| 1 | 50 | 20 | 40 |
| 2 | 100 | 80 | 60 |
| 3 | 150 | 150 | 200 |
| 4 | 350 | 300 | 400 |
| 5 | 200 | 150 | 250 |
| 6 | 150 | 100 | 150 |
Define:
1.variance for each enterprise (intragroup variance);
2. the average of intragroup variances;
3. intergroup variance;
4. total variance.
Solution.
Before proceeding with the solution of the problem, it is necessary to find out which feature is effective and which is factorial. In the example under consideration, the effective attribute is "Tariff category", and the factor attribute is "Number (name) of the enterprise".
Then we have three groups (enterprises), for which it is necessary to calculate the group average and intragroup variances:

| Company | Group average, | Intra-group variance, |
| 1 | 4 | 1,8 |
Average of intragroup variances ( residual variance) will be calculated by the formula:
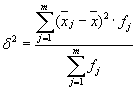
where can you calculate:
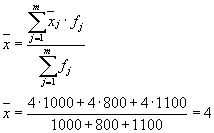
or:
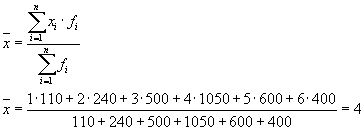
then:
The total variance will be equal to: s 2 = 1.6 + 0 = 1.6.
The total variance can also be calculated using one of the following two formulas:

When solving practical problems, one often has to deal with a feature that takes only two alternative meanings. In this case, they do not speak about the weight of a particular value of the attribute, but about its share in the aggregate. If the proportion of units in the population possessing the trait under study is denoted by “ R", And not possessing - through" q", Then the variance can be calculated by the formula:
s 2 = p × q
Example No. 2. Based on the data on the output of six workers in a team, determine the intergroup variance and assess the impact of the work shift on their labor productivity if the total variance is 12.2.
| Work brigade number | Worker production, pcs. | |
| in the 1st shift | during the second shift | |
| 1 | 18 | 13 |
| 2 | 19 | 14 |
| 3 | 22 | 15 |
| 4 | 20 | 17 |
| 5 | 24 | 16 |
| 6 | 23 | 15 |
Solution... Initial data
| X | f 1 | f 2 | f 3 | f 4 | f 5 | f 6 | Total |
| 1 | 18 | 19 | 22 | 20 | 24 | 23 | 126 |
| 2 | 13 | 14 | 15 | 17 | 16 | 15 | 90 |
| Total | 31 | 33 | 37 | 37 | 40 | 38 |
Then we have 6 groups for which it is necessary to calculate the group mean and intragroup variances.
1. Find the average values of each group.
2. Find the mean square of each group.
The calculation results are summarized in the table:
| Group number | Group average | Intra-group variance |
| 1 | 1.42 | 0.24 |
| 2 | 1.42 | 0.24 |
| 3 | 1.41 | 0.24 |
| 4 | 1.46 | 0.25 |
| 5 | 1.4 | 0.24 |
| 6 | 1.39 | 0.24 |
3. Intra-group variance characterizes the change (variation) of the studied (effective) trait within the group under the influence of all factors on it, except for the factor underlying the grouping:
The average of the intragroup variances is calculated by the formula:
4. Intergroup variance characterizes the change (variation) of the studied (effective) trait under the influence of the factor (factor trait) on it, which is the basis of the grouping.
Intergroup variance is defined as:
where
Then
Total variance characterizes the change (variation) of the studied (effective) attribute under the influence of all factors (factor attributes) without exception. By the condition of the problem, it is equal to 12.2.
Empirical correlation relation measures how much of the overall variability of the effective trait is caused by the factor under study. This is the ratio of factor variance to total variance:
Determine the empirical correlation ratio:
The connections between signs can be weak and strong (close). Their criteria are assessed on the Chaddock scale:
0.1 0.3 0.5 0.7 0.9 In our example, the relationship between trait Y and factor X is weak
Determination coefficient.
Let's define the coefficient of determination:
Thus, 0.67% of the variation is due to differences between traits, and 99.37% - other factors.
Output: in this case, the production of workers does not depend on the work in a particular shift, i.e. the impact of the work shift on their labor productivity is not significant and is due to other factors.
Example No. 3. Based on average wages and the squares of the deviations from its value for two groups of workers, find the total variance by applying the rule for adding variances:
Solution:Average of within-group variances
Intergroup variance is defined as:
The total variance will be: 480 + 13824 = 14304
We calculate inMSEXCELvariance and standard deviation sampling. We also calculate the variance of a random variable if its distribution is known.
Consider first variance, then standard deviation.
Sample variance
Sample variance (sample variance,samplevariance) characterizes the spread of values in the array relative to.
All 3 formulas are mathematically equivalent.
From the first formula it is seen that sample variance is the sum of the squared deviations of each value in the array from average divided by sample size minus 1.
variance sampling the function DISP () is used. VAR name, i.e. VARiance. Since the MS EXCEL 2010 version it is recommended to use its analogue DISP.B (), eng. the name VARS, i.e. Sample VARiance. In addition, since the MS EXCEL 2010 version there is a DISP.G (), English function. the name of the VARP, i.e. Population VARiance, which calculates variance for the general population ... All the difference comes down to the denominator: instead of n-1 as in DISP.B (), DISP.G () has just n in the denominator. Before MS EXCEL 2010, the VARP () function was used to calculate the variance of the general population.
Sample variance
= SQUARE (Sample) / (COUNT (Sample) -1)
= (SUM (Sample) -COUNT (Sample) * AVERAGE (Sample) ^ 2) / (COUNT (Sample) -1)- the usual formula
= SUM ((Sample -VALUE (Sample)) ^ 2) / (COUNT (Sample) -1) –
Sample variance is equal to 0, only if all values are equal to each other and, accordingly, are equal average... Usually, the larger the value variance, the greater the spread of values in the array.
Sample variance is a point estimate variance distribution of the random variable from which the sample... About building confidence intervals when evaluating variance can be read in the article.
Variance of a random variable
To calculate variance random variable, you need to know it.
For variance random variable X is often used notation Var (X). Dispersion equal to the square of the deviation from the mean E (X): Var (X) = E [(X-E (X)) 2]
dispersion calculated by the formula:

where x i is the value that the random variable can take, and μ is the average value (), p (x) is the probability that the random variable will take the value x.
If the random variable has, then dispersion calculated by the formula:

Dimension variance corresponds to the square of the unit of measure of the original values. For example, if the values in the sample are measurements of the weight of the part (in kg), then the dimension of the variance will be kg 2. This can be difficult to interpret, therefore, to characterize the spread of values, a value equal to the square root of variance – standard deviation.
Some properties variance:
Var (X + a) = Var (X), where X is a random variable and a is a constant.
Var (aX) = a 2 Var (X)
Var (X) = E [(XE (X)) 2] = E = E (X 2) -E (2 * X * E (X)) + (E (X)) 2 = E (X 2) - 2 * E (X) * E (X) + (E (X)) 2 = E (X 2) - (E (X)) 2
This variance property is used in article about linear regression.
Var (X + Y) = Var (X) + Var (Y) + 2 * Cov (X; Y), where X and Y - random variables, Cov (X; Y) is the covariance of these random variables.
If the random variables are independent, then their covariance is equal to 0, and, therefore, Var (X + Y) = Var (X) + Var (Y). This variance property is used in output.
Let us show that for independent quantities Var (X-Y) = Var (X + Y). Indeed, Var (X-Y) = Var (X-Y) = Var (X + (- Y)) = Var (X) + Var (-Y) = Var (X) + Var (-Y) = Var ( X) + (- 1) 2 Var (Y) = Var (X) + Var (Y) = Var (X + Y). This variance property is used for plotting.
Sample standard deviation
Sample standard deviation is a measure of how widely the values in the sample are scattered relative to theirs.
A-priory, standard deviation equals the square root of variance:

Standard deviation does not take into account the magnitude of the values in sample, but only the degree of dispersion of values around them middle... Here's an example to illustrate this.
Let's calculate the standard deviation for 2 samples: (1; 5; 9) and (1001; 1005; 1009). In both cases, s = 4. Obviously, the ratio of the standard deviation to the values of the array is significantly different for the samples. For such cases, use The coefficient of variation(Coefficient of Variation, CV) - ratio Standard deviation to the middle arithmetic expressed as a percentage.
In MS EXCEL 2007 and earlier, for calculating Sample standard deviation the function is used = STDEV (), eng. name STDEV, i.e. STandard DEViation. Since version MS EXCEL 2010 it is recommended to use its analogue = STDEV.V (), eng. the name STDEV.S, i.e. Sample STandard DEViation.
In addition, starting from the MS EXCEL 2010 version there is a function STDEV.G (), eng. name STDEV.P, i.e. Population STandard DEViation, which calculates standard deviation for the general population... All the difference comes down to the denominator: instead of n-1 like STDEV.V (), STDEV.G () has just n in the denominator.
Standard deviation can also be calculated directly by the following formulas (see example file)
= ROOT (SQUARE (Sample) / (COUNT (Sample) -1))
= ROOT ((SUM (Sample) -COUNT (Sample) * AVERAGE (Sample) ^ 2) / (COUNT (Sample) -1))
Other spread measures
The SQUARE () function calculates with umma squared deviations of values from their middle... This function will return the same result as the formula = DISP.G ( Sample)*CHECK( Sample) , where Sample- reference to a range containing an array of sample values (). Calculations in the function SQUARE () are made according to the formula:

The AVEDEV () function is also a measure of the spread of a set of data. The AVEDV () function calculates the average of the absolute values of deviations of values from middle... This function will return the same result as the formula = SUMPRODUCT (ABS (Sample-AVERAGE (Sample))) / COUNT (Sample), where Sample- a reference to a range containing an array of sample values.
Calculations in the function AVEDV () are made according to the formula:

Variational swing (or swing of variation) - this is the difference between the maximum and minimum values of the characteristic:
In our example, the range of variation in the shift work of workers is: in the first brigade R = 105-95 = 10 children, in the second brigade R = 125-75 = 50 children. (5 times more). This suggests that the output of the 1st brigade is more "stable", but the second brigade has more reserves for the growth of output, because if all workers reach the maximum output for this brigade, it can produce 3 * 125 = 375 parts, and in the 1st brigade only 105 * 3 = 315 parts.
If the extreme values of the characteristic are not typical for the population, then the quartile or decile ranges are used. The quartile range RQ = Q3-Q1 covers 50% of the population, the decile range of the first RD1 = D9-D1 covers 80% of the data, the second decile range of RD2 = D8-D2 is 60%.
Lack of indicator variation range is, but that its value does not reflect all the fluctuations of the attribute.
The simplest generalizing indicator that reflects all fluctuations of a feature is mean linear deviation, which is the arithmetic mean of the absolute deviations of individual options from their mean:
,
for grouped data ![]() ,
,
where xi is the value of the feature in discrete row or the middle of an interval in an interval distribution.
In the above formulas, the differences in the numerator are taken modulo, otherwise, according to the property of the arithmetic mean, the numerator will always be is zero... Therefore, the average linear deviation in statistical practice is rarely used, only in those cases when the summation of indicators without taking into account the sign makes economic sense. With its help, for example, the composition of employees, the profitability of production, and the turnover of foreign trade are analyzed.
Feature variance Is the mean square of the deviations of the variant from their mean value:
simple variance ![]() ,
,
weighted variance  .
.
The formula for calculating variance can be simplified:
Thus, the variance is equal to the difference between the mean of the squares of the variant and the square of the mean of the variant of the population:  .
.
However, due to the summation of the squares of the deviations, the variance gives a distorted idea of the deviations, therefore, it is calculated on the basis of the mean standard deviation
, which shows how much, on average, specific variants of a feature deviate from their average value. Calculated by taking the square root of the variance:
for ungrouped data  ,
,
for the variation series 
The smaller the variance and standard deviation, the more homogeneous the population, the more reliable (typical) the mean will be.
Linear mean and mean standard deviation- named numbers, that is, they are expressed in units of measure of the attribute, are identical in content and close in value.
Calculate absolute indicators variations are recommended using tables.
Table 3 - Calculation of the characteristics of the variation (using the example of the period of data on the shift production of the work crew)
Number of workers |
The middle of the interval, |
Calculated values |
|||||
Total: |
|||||||
Average shift production of workers: ![]()
Average linear deviation: ![]()
Dispersion of production: 
The standard deviation of the output of individual workers from the average output:
.
1 Calculation of variance by the method of moments
Calculation of variances is associated with cumbersome calculations (especially if the average value is expressed a large number with several decimal places). Calculations can be simplified by using a simplified formula and dispersion properties.
The dispersion has the following properties:
- if all the values of the attribute are reduced or increased by the same value A, then the variance will not decrease from this:
 ,
,
 then or
then or 
Using the properties of the variance and first decreasing all the variants of the population by the value A, and then dividing by the value of the interval h, we obtain the formula for calculating the variance in the variational series with at equal intervals way of moments: ,
,
where is the variance calculated by the method of moments;
h is the value of the interval of the variation series;
- new (converted) values option;
A - constant value, which is used as the middle of the interval with the highest frequency; or the variant with the highest frequency; 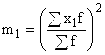 - square of the moment of the first order;
- square of the moment of the first order;
- moment of the second order.
Let's calculate the variance by the method of moments based on the data on the shift production of the working team.
Table 4 - Calculation of variance by the method of moments
Groups of workers for development, pcs. |
Number of workers |
The middle of the interval, |
Calculated values |
||
Calculation procedure:


- we calculate the variance:
2 Calculation of the variance of an alternative feature
Among the features studied by statistics, there are those that are characterized by only two mutually exclusive values. These are alternative signs. They are assigned two quantitative meanings, respectively: options 1 and 0. Frequency of options 1, which is denoted by p, is the proportion of units that have this feature. The difference 1-p = q is a frequency of options 0. Thus,
xi |
|
The arithmetic mean of the alternative feature ![]() , since p + q = 1.
, since p + q = 1.
Variance of an alternative feature
since 1-p = q
Thus, the variance of an alternative feature is equal to the product of the fraction of units that have this feature and the fraction of units that do not have this feature.
If the values 1 and 0 occur equally often, i.e. p = q, the variance reaches its maximum pq = 0.25.
The variance of an alternative characteristic is used in sample surveys, for example, product quality.
3 Intergroup variance. Variance addition rule
Variance, unlike other characteristics of variation, is an additive quantity. That is, in the aggregate, which is divided into groups by factor NS , performance trait variance y can be decomposed into variance in each group (intragroup) and variance between groups (intergroup). Then, along with the study of the variation of the trait for the entire population as a whole, it becomes possible to study the variation in each group, as well as between these groups.
Total variance measures the variation of a trait at in the aggregate under the influence of all factors that caused this variation (deviations). It is equal to the mean square of the deviations of individual values of the attribute at from the total average and can be calculated as a simple or weighted variance.
Intergroup variance characterizes the variation of the effective trait at caused by the influence of the sign factor NS, which is the basis of the grouping. It characterizes the variation of group means and is equal to the mean square of deviations of group means from the total mean:  ,
,
where is the arithmetic mean of the i-th group;
- the number of units in the i-th group (frequency of the i-th group);
- the total average of the population.
Intra-group variance reflects random variation, that is, that part of the variation that is caused by the influence of unaccounted factors and does not depend on the attribute-factor underlying the grouping. It characterizes the variation of individual values relative to group means, is equal to the mean square of deviations of individual values of the attribute at within a group from the arithmetic mean of this group (group mean) and is calculated as a simple or weighted variance for each group: ![]() or
or ![]() ,
,
where is the number of units in the group.
Based on intragroup variances for each group, it is possible to determine the total mean of within-group variances:
.
The relationship between the three variances is called variance addition rules, according to which the total variance is equal to the sum intergroup variance and the average of the intragroup variances:
Example... When studying the influence tariff category(qualifications) of workers to the level of their labor productivity, the following data were obtained.
Table 5 - Distribution of workers by average hourly production.
№ p / p |
Workers of the 4th category |
Workers of the 5th category |
|||||
Production |
Production |
||||||
1 |
7 |
7-10=-3 |
9 |
1 |
14 |
14-15=-1 |
1 |
V this example workers are divided into two groups by factor NS- qualifications, which is characterized by their category. The effective sign - development - varies both under its influence (intergroup variation) and due to other random factors (intragroup variation). The challenge is to measure these variations using three variances: total, between-group and within-group. The empirical coefficient of determination shows the proportion of variation of the effective trait at under the influence of a factor NS... The rest of the total variation at caused by a change in other factors.
In the example, the empirical coefficient of determination is: ![]() or 66.7%,
or 66.7%,
This means that 66.7% of the variation in workers' labor productivity is due to differences in qualifications, and 33.3% - the influence of other factors.
Empirical correlation relation shows the tightness of the relationship between grouping and effective indicators. Calculated as the square root of the empirical coefficient of determination:
The empirical correlation ratio, like and, can take values from 0 to 1.
If there is no connection, then = 0. In this case = 0, that is, the group means are equal to each other and there is no intergroup variation. This means that the grouping sign is that the factor does not affect the formation of the general variation.
If the connection is functional, then = 1. In this case, the variance of the group means is equal to the total variance (), that is, there is no intra-group variation. This means that the grouping attribute completely determines the variation of the studied productive attribute.
How closer meaning the correlation relation to the unit, the closer, closer to the functional dependence of the relationship between the signs.
For a qualitative assessment of the tightness of the relationship between the signs, the Chaddock ratios are used.
In the example ![]() , which indicates a close relationship between the productivity of workers and their qualifications.
, which indicates a close relationship between the productivity of workers and their qualifications.
Often in statistics, when analyzing a phenomenon or process, it is necessary to take into account not only information about the average levels of the studied indicators, but also spread or variation in values of individual units , which is an important characteristic of the target population.
Stock prices, supply and demand volumes, interest rates at different times and in different places are subject to the greatest variation.
The main indicators characterizing the variation , are the range, variance, standard deviation and coefficient of variation.
Swipe variation is the difference between the maximum and minimum values of the attribute: R = Xmax - Xmin... Disadvantage this indicator is that it evaluates only the boundaries of variation of the feature and does not reflect its fluctuations within these boundaries.
Dispersion is devoid of this drawback. It is calculated as the mean square of the deviations of the characteristic values from their average value:
Simplified way to calculate variance is carried out using the following formulas (simple and weighted):
Examples of using these formulas are presented in tasks 1 and 2.
A widely used indicator in practice is standard deviation :
The standard deviation is defined as Square root from the variance and has the same dimension as the studied attribute.
The considered indicators make it possible to obtain absolute value variations, i.e. evaluate it in the units of the studied attribute. Unlike them, the coefficient of variation measures fluctuations in relative terms - relative to the average level, which in many cases is preferable.
Formula for calculating the coefficient of variation.
Examples of solving problems on the topic "Indicators of variation in statistics"
Problem 1 ... When studying the influence of advertising on the size of the average monthly deposit in the banks of the region, 2 banks were examined. The following results were obtained:
Define:
1) for each bank: a) the average size of the deposit for the month; b) variance of the contribution;
2) the average monthly deposit for two banks together;
3) Dispersion of the deposit for 2 banks, depending on advertising;
4) Dispersion of the deposit for 2 banks, depending on all factors, except advertising;
5) Total variance using the addition rule;
6) Coefficient of determination;
7) Correlation ratio.
Solution
1) Let's compose a calculation table for a bank with advertising ... To determine the average size of the deposit for a month, we will find the midpoints of the intervals. In this case, the value of the open interval (the first) is conditionally equated to the value of the interval adjacent to it (the second).
We find the average size of the contribution by the formula of the arithmetic weighted average:
29,000/50 = 580 rubles.
We find the variance of the contribution by the formula:
23 400/50 = 468
We will perform similar actions for a bank without advertising :
2) Let's find the average size of the deposit for two banks together. Xav = (580 × 50 + 542.8 × 50) / 100 = 561.4 rubles.
3) The variance of the contribution, for two banks, depending on advertising, we find by the formula: σ 2 = pq (the formula for the variance of the alternative feature). Here p = 0.5 is the proportion of factors that depend on advertising; q = 1-0.5, then σ 2 = 0.5 * 0.5 = 0.25.
4) Since the share of other factors is 0.5, the variance of the contribution for the two banks, which depends on all factors except advertising, is also 0.25.
5) Determine the total variance using the addition rule.
= (468*50+636,16*50)/100=552,08
= [(580-561,4)250+(542,8-561,4)250] / 100= 34 596/ 100=345,96
σ 2 = σ 2 fact + σ 2 rest = 552.08 + 345.96 = 898.04
6) The coefficient of determination η 2 = σ 2 fact / σ 2 = 345.96 / 898.04 = 0.39 = 39% - the size of the contribution depends on advertising by 39%.
7) Empirical correlation ratio η = √η 2 = √0.39 = 0.62 - the relationship is quite close.
Task 2 ... There is a grouping of enterprises according to the size of marketable products:
Determine: 1) the variance of the value of marketable products; 2) standard deviation; 3) coefficient of variation.
Solution
1) By condition, an interval distribution series is presented. It must be expressed discretely, that is, find the middle of the interval (x "). In groups of closed intervals, we will find the middle by a simple arithmetic mean. In groups with an upper boundary, as the difference between this upper boundary and half the size of the interval following it (200- (400 -200): 2 = 100).
In groups with a lower border - the sum of this lower border and half of the size of the previous interval (800+ (800-600): 2 = 900).
We calculate the average value of marketable products using the formula:
Xav = k × ((Σ ((x "-a): k) × f): Σf) + a. Here a = 500 is the size of the variant at the highest frequency, k = 600-400 = 200 is the size of the interval at the highest frequency . Place the result in the table:
So, the average value of marketable output for the period under study is generally equal to Xav = (-5: 37) × 200 + 500 = 472.97 thousand rubles.
2) We find the variance by the following formula:
σ 2 = (33/37) * 2002- (472.97-500) 2 = 35 675.67-730.62 = 34 945.05
3) standard deviation: σ = ± √σ 2 = ± √34 945.05 ≈ ± 186.94 thousand rubles.
4) coefficient of variation: V = (σ / Xav) * 100 = (186.94 / 472.97) * 100 = 39.52%
According to the sample survey, the depositors were grouped according to the size of their deposit in the city's Sberbank:
Define:
1) the range of variation;
2) the average size of the deposit;
3) average linear deviation;
4) variance;
5) standard deviation;
6) coefficient of variation of contributions.
Solution:
This distribution series contains open intervals. In such series, the value of the interval of the first group is conventionally assumed to be equal to the value of the interval of the next one, and the value of the interval of the last group is equal to the value of the interval of the previous one.
The value of the interval of the second group is equal to 200, therefore, the value of the first group is also equal to 200. The value of the interval of the penultimate group is equal to 200, which means that the last interval will have a value of 200.
1) Let's define the range of variation as the difference between the largest and the smallest value of the feature:
The range of variation in the size of the deposit is 1000 rubles.
2) The average size of the contribution is determined by the formula of the arithmetic weighted average.
Let's preliminarily define the discrete value of the feature in each interval. To do this, we find the midpoints of the intervals using the formula for the arithmetic prime.
The average value of the first interval will be equal to:

the second - 500, etc.
Let's enter the results of the calculations into the table:
| Deposit amount, rub. | Number of depositors, f | Middle of the interval, x | xf |
|---|---|---|---|
| 200-400 | 32 | 300 | 9600 |
| 400-600 | 56 | 500 | 28000 |
| 600-800 | 120 | 700 | 84000 |
| 800-1000 | 104 | 900 | 93600 |
| 1000-1200 | 88 | 1100 | 96800 |
| Total | 400 | - | 312000 |
The average size of a deposit in the city's Sberbank will be equal to 780 rubles:
3) The average linear deviation is the arithmetic mean of the absolute deviations of individual values of the attribute from the total average:

The procedure for calculating the mean linear deviation in the interval distribution series is as follows:
1. Calculate the weighted arithmetic mean, as shown in item 2).
2. The absolute deviations of the variant from the mean are determined:
3. The resulting deviations are multiplied by the frequencies:
4. Find the sum of the weighted deviations without taking into account the sign:
5. The sum of the weighted deviations is divided by the sum of the frequencies:
It is convenient to use the calculated data table:
| Deposit amount, rub. | Number of depositors, f | Middle of the interval, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 480 | 15360 |
| 400-600 | 56 | 500 | -280 | 280 | 15680 |
| 600-800 | 120 | 700 | -80 | 80 | 9600 |
| 800-1000 | 104 | 900 | 120 | 120 | 12480 |
| 1000-1200 | 88 | 1100 | 320 | 320 | 28160 |
| Total | 400 | - | - | - | 81280 |

The average linear deviation of the size of the deposit of Sberbank clients is 203.2 rubles.
4) Dispersion is the arithmetic mean of the squares of the deviations of each feature value from the arithmetic mean.
Calculation of variance in interval rows distribution is made according to the formula:

The procedure for calculating the variance in this case is as follows:
1. Determine the weighted arithmetic mean, as shown in clause 2).
2. Find the deviation of the variant from the mean:
3. Square the deviation of each option from the mean:
4. Multiply the squares of the deviations by the weights (frequencies):
![]()
5. Summarize the works received:
![]()
6. The resulting sum is divided by the sum of the weights (frequencies):

Let's fill out the calculations in the table:
| Deposit amount, rub. | Number of depositors, f | Middle of the interval, x | |||
|---|---|---|---|---|---|
| 200-400 | 32 | 300 | -480 | 230400 | 7372800 |
| 400-600 | 56 | 500 | -280 | 78400 | 4390400 |
| 600-800 | 120 | 700 | -80 | 6400 | 768000 |
| 800-1000 | 104 | 900 | 120 | 14400 | 1497600 |
| 1000-1200 | 88 | 1100 | 320 | 102400 | 9011200 |
| Total | 400 | - | - | - | 23040000 |

