Determine the variance. Mathematical expectation of a discrete random variable
The main generalizing indicators of variation in statistics are variances and mean standard deviation.
Dispersion it arithmetic mean squared deviations of each feature value from the total mean. The variance is usually called the mean square of the deviations and is denoted 2 . Depending on the initial data, the variance can be calculated from the arithmetic mean, simple or weighted:
unweighted (simple) dispersion;
 weighted variance.
weighted variance.
Standard deviation is a generalizing characteristic of absolute dimensions variations trait in the aggregate. It is expressed in the same units as the sign (in meters, tons, percent, hectares, etc.).
The standard deviation is the square root of the variance and is denoted by :
 unweighted standard deviation;
unweighted standard deviation;
 weighted standard deviation.
weighted standard deviation.
The standard deviation is a measure of the reliability of the mean. The smaller the standard deviation, the better the arithmetic mean reflects the entire represented population.
The calculation of the standard deviation is preceded by the calculation of the variance.
The procedure for calculating the weighted variance is as follows:
1) determine the arithmetic weighted average:
2) calculate the deviations of the options from the average:
3) square the deviation of each option from the mean:
4) multiply squared deviations by weights (frequencies):
5) summarize the received works:
![]()
6) the resulting amount is divided by the sum of the weights:

Example 2.1

Calculate the arithmetic weighted average:

The values of deviations from the mean and their squares are presented in the table. Let's define the variance:

The standard deviation will be equal to:

If the source data is presented as an interval distribution series , then you first need to determine the discrete value of the feature, and then apply the method described.
Example 2.2
Let us show the calculation of the variance for the interval series on the data on the distribution of the sown area of the collective farm by wheat yield.

The arithmetic mean is:

Let's calculate the variance:

6.3. Calculation of the dispersion according to the formula for individual data
Calculation technique dispersion complicated, and large values options and frequencies can be cumbersome. Calculations can be simplified using the dispersion properties.
The dispersion has the following properties.
1. A decrease or increase in the weights (frequencies) of a variable feature by a certain number of times does not change the dispersion.
2. Decreasing or increasing each feature value by the same constant value A dispersion does not change.
3. Decreasing or increasing each feature value by a certain number of times k respectively reduces or increases the variance in k 2 times standard deviation in k once.
4. The variance of a feature relative to an arbitrary value is always greater than the variance relative to the arithmetic mean by the square of the difference between the average and arbitrary values:
![]()
If A 0, then we arrive at the following equality:
i.e., the variance of a feature is equal to the difference between the mean square of the feature values and the square of the mean.
Each property can be used alone or in combination with others when calculating the variance.
The procedure for calculating the variance is simple:
1) determine arithmetic mean :
2) square the arithmetic mean:

3) square the deviation of each variant of the series:
X i 2 .
4) find the sum of squares of options:
5) divide the sum of squares of options by their number, i.e. determine the average square:
6) determine the difference between the mean square of the feature and the square of the mean:
Example 3.1 We have the following data on the productivity of workers:

Let's make the following calculations:
![]()
Along with the study of the variation of a trait throughout the entire population as a whole, it is often necessary to trace quantitative changes trait by groups into which the population is divided, as well as between groups. This study of variation is achieved through the calculation and analysis various kinds dispersion.
Distinguish between total, intergroup and intragroup dispersion.
Total variance σ 2 measures the variation of a trait over the entire population under the influence of all the factors that caused this variation, .
Intergroup variance (δ) characterizes systematic variation, i.e. differences in the magnitude of the trait under study, arising under the influence of the trait-factor underlying the grouping. It is calculated by the formula: 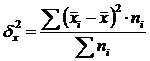 .
.
Within-group variance (σ) reflects random variation, i.e. part of the variation that occurs under the influence of unaccounted for factors and does not depend on the trait-factor underlying the grouping. It is calculated by the formula: 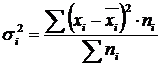 .
.
Average of within-group variances:  .
.
There is a law linking 3 types of dispersion. The total variance is equal to the sum of the average of the intragroup and intergroup variance: ![]() .
.
This ratio is called variance addition rule.
In the analysis, a measure is widely used, which is the proportion of between-group variance in the total variance. It bears the name empirical coefficient of determination (η 2): .
The square root of the empirical coefficient of determination is called empirical correlation ratio (η):
 .
.
It characterizes the influence of the attribute underlying the grouping on the variation of the resulting attribute. The empirical correlation ratio varies from 0 to 1.
We will show its practical use in the following example (Table 1).
Example #1. Table 1 - Labor productivity of two groups of workers of one of the workshops of NPO "Cyclone"
Calculate the total and group averages and variances:
The initial data for calculating the average of the intragroup and intergroup dispersion are presented in Table. 2.
table 2
Calculation and δ 2 for two groups of workers.
|
Worker groups | Number of workers, pers. | Average, det./shift. | Dispersion |
| Passed technical training | 5 | 95 | 42,0 |
| Not technically trained | 5 | 81 | 231,2 |
| All workers | 10 | 88 | 185,6 |
 .
.
Intergroup variance
Total variance:
Thus, the empirical correlation ratio: .
Along with the variation of quantitative traits, a variation of qualitative traits can also be observed. This study of variation is achieved by calculating the following types of variances:
The intra-group variance of the share is determined by the formula
where n i– the number of units in separate groups.The proportion of the studied trait in the entire population, which is determined by the formula:
The three types of dispersion are related to each other as follows:
This ratio of variances is called the feature share variance addition theorem.
In many cases, it becomes necessary to introduce another numerical characteristic to measure the degree dispersion, spread of values, taken as a random variable ξ , around its mathematical expectation.
Definition. dispersion random variable ξ called a number.
D= M(ξ-M ξ) 2 . (1)
In other words, the dispersion is expected value the square of the deviation of the values of a random variable from its mean value.
called mean square deviation
quantities ξ .
If the variance characterizes the average size of the squared deviation ξ from Mξ, then the number can be considered as some average characteristic of the deviation itself, more precisely, the quantity | ξ-Mξ |.
Definition (1) implies the following two properties of the dispersion.
1. The dispersion of a constant value is zero. This is quite consistent with the visual meaning of dispersion, as a "measure of spread".
Indeed, if
ξ \u003d C, then Mξ = C and that means Dξ = M(C-C) 2 = M 0 = 0.
2. When multiplying a random variable ξ by a constant number C, its variance is multiplied by C 2
D(Cξ) = C 2 Dξ . (3)
Really
D(Cξ) = M(C ![]()
= M(C .
3. There is the following formula for calculating the variance:
![]() . (4)
. (4)
The proof of this formula follows from the properties of the mathematical expectation.
We have:

4. If the values ξ 1 and ξ 2 are independent, then the variance of their sum is equal to the sum of their variances:
Proof . For the proof, we use the properties of mathematical expectation. Let Mξ 1 = m 1 , Mξ 2 = m 2 then.

Formula (5) is proved.
Since the variance of a random variable is, by definition, the mathematical expectation of the value ( ξ-m) 2 , where m = Mξ , then to calculate the variance, you can use the formulas obtained in Section 7, Chapter II.
So if ξ there is a DSV with a distribution law
| x 1 | x 2 | ... |
| p 1 | p 2 | ... |
then we will have:
![]() . (7)
. (7)
If ξ continuous random variable with distribution density p(x), then we get:
Dξ= ![]() . (8)
. (8)
If formula (4) is used to calculate the variance, then other formulas can be obtained, namely:
![]() , (9)
, (9)
if the value ξ discrete, and
Dξ= ![]() , (10)
, (10)
if ξ distributed with density p(x).
Example 1 . Let the value ξ is uniformly distributed on the interval [ a,b]. Using formula (10) we get:

It can be shown that the variance of a random variable distributed according to the normal law with density
p(x)= , (11)
is equal to σ 2 .
Thus, the meaning of the parameter σ, which enters into the expression for density (11) for the normal law, is clarified; σ there is an average standard deviation quantities ξ.
Example 2 . Find the variance of a random variable ξ distributed according to the binomial law.
Solution . Using the representation of ξ in the form
ξ = ξ 1 + ξ 2 + n(see example 2 §7 ch. II) and applying the formula for adding variances for independent quantities, we obtain
Dξ = Dξ 1 + Dξ 2 + Dξn .
Dispersion of any of the quantities ξi (i= 1,2, n) is calculated directly:
Dξi = M(ξi) 2 - (Mξ i) 2 = 0 2 q+ 1 2 p- p 2 = p(1-p) = pq.
Finally we get
Dξ= npq, where q = 1 -p.
The mathematical expectation (average value) of a random variable X , given on a discrete probability space, is the number m =M[X]=∑x i p i , if the series converges absolutely.
Service assignment. With an online service the mathematical expectation, variance and standard deviation are calculated(see example). In addition, a graph of the distribution function F(X) is plotted.
Properties of the mathematical expectation of a random variable
- The mathematical expectation of a constant value is equal to itself: M[C]=C , C is a constant;
- M=C M[X]
- The mathematical expectation of the sum of random variables is equal to the sum of their mathematical expectations: M=M[X]+M[Y]
- The mathematical expectation of the product of independent random variables is equal to the product of their mathematical expectations: M=M[X] M[Y] if X and Y are independent.
Dispersion Properties
- The dispersion of a constant value is equal to zero: D(c)=0.
- The constant factor can be taken out from under the dispersion sign by squaring it: D(k*X)= k 2 D(X).
- If random variables X and Y are independent, then the variance of the sum is equal to the sum of the variances: D(X+Y)=D(X)+D(Y).
- If random variables X and Y are dependent: D(X+Y)=DX+DY+2(X-M[X])(Y-M[Y])
- For the variance, the computational formula is valid:
D(X)=M(X 2)-(M(X)) 2
Example. The mathematical expectations and variances of two independent random variables X and Y are known: M(x)=8 , M(Y)=7 , D(X)=9 , D(Y)=6 . Find the mathematical expectation and variance of the random variable Z=9X-8Y+7 .
Solution. Based on the properties of mathematical expectation: M(Z) = M(9X-8Y+7) = 9*M(X) - 8*M(Y) + M(7) = 9*8 - 8*7 + 7 = 23 .
Based on the dispersion properties: D(Z) = D(9X-8Y+7) = D(9X) - D(8Y) + D(7) = 9^2D(X) - 8^2D(Y) + 0 = 81*9 - 64*6 = 345
Algorithm for calculating the mathematical expectation
Properties of discrete random variables: all their values can be renumbered natural numbers; Assign each value a non-zero probability.- Multiply the pairs one by one: x i by p i .
- We add the product of each pair x i p i .
For example, for n = 4: m = ∑x i p i = x 1 p 1 + x 2 p 2 + x 3 p 3 + x 4 p 4
Example #1.
| x i | 1 | 3 | 4 | 7 | 9 |
| pi | 0.1 | 0.2 | 0.1 | 0.3 | 0.3 |
The mathematical expectation is found by the formula m = ∑x i p i .
Mathematical expectation M[X].
M[x] = 1*0.1 + 3*0.2 + 4*0.1 + 7*0.3 + 9*0.3 = 5.9
The dispersion is found by the formula d = ∑x 2 i p i - M[x] 2 .
Dispersion D[X].
D[X] = 1 2 *0.1 + 3 2 *0.2 + 4 2 *0.1 + 7 2 *0.3 + 9 2 *0.3 - 5.9 2 = 7.69
Standard deviation σ(x).
σ = sqrt(D[X]) = sqrt(7.69) = 2.78
Example #2. A discrete random variable has the following distribution series:
| X | -10 | -5 | 0 | 5 | 10 |
| R | a | 0,32 | 2a | 0,41 | 0,03 |
Solution. The value a is found from the relationship: Σp i = 1
Σp i = a + 0.32 + 2 a + 0.41 + 0.03 = 0.76 + 3 a = 1
0.76 + 3 a = 1 or 0.24=3 a , whence a = 0.08
Example #3. Determine the distribution law of a discrete random variable if its variance is known, and x 1
p 1 =0.3; p2=0.3; p3=0.1; p 4 \u003d 0.3
d(x)=12.96
Solution.
Here you need to make a formula for finding the variance d (x) :
d(x) = x 1 2 p 1 +x 2 2 p 2 +x 3 2 p 3 +x 4 2 p 4 -m(x) 2
where expectation m(x)=x 1 p 1 +x 2 p 2 +x 3 p 3 +x 4 p 4
For our data
m(x)=6*0.3+9*0.3+x 3 *0.1+15*0.3=9+0.1x 3
12.96 = 6 2 0.3+9 2 0.3+x 3 2 0.1+15 2 0.3-(9+0.1x 3) 2
or -9/100 (x 2 -20x+96)=0
Accordingly, it is necessary to find the roots of the equation, and there will be two of them.
x 3 \u003d 8, x 3 \u003d 12
We choose the one that satisfies the condition x 1
Distribution law of a discrete random variable
x 1 =6; x2=9; x 3 \u003d 12; x4=15
p 1 =0.3; p2=0.3; p3=0.1; p 4 \u003d 0.3
Steps
Sample Variance Calculation
-
Record the sample values. In most cases, only samples of certain populations are available to statisticians. For example, as a rule, statisticians do not analyze the cost of maintaining the population of all cars in Russia - they analyze a random sample of several thousand cars. Such a sample will help determine the average cost per car, but most likely, the resulting value will be far from the real one.
- For example, let's analyze the number of buns sold in a cafe in 6 days, taken in random order. The sample has the following form: 17, 15, 23, 7, 9, 13. This is a sample, not a population, because we do not have data on the sold buns for each day the cafe is open.
- If you are given a population and not a sample of values, skip to the next section.
-
Write down the formula for calculating the sample variance. Dispersion is a measure of the spread of values of some quantity. The closer the dispersion value is to zero, the closer the values are grouped together. When working with a sample of values, use the following formula to calculate the variance:
- s 2 (\displaystyle s^(2)) = ∑[(x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))] / (n - 1)
- s 2 (\displaystyle s^(2)) is the dispersion. Dispersion is measured in square units.
- x i (\displaystyle x_(i))- each value in the sample.
- x i (\displaystyle x_(i)) you need to subtract x̅, square it, and then add the results.
- x̅ – sample mean (sample mean).
- n is the number of values in the sample.
-
Calculate the sample mean. It is denoted as x̅. The sample mean is computed like a normal arithmetic mean: add up all the values in the sample, and then divide the result by the number of values in the sample.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
Now divide the result by the number of values in the sample (in our example there are 6): 84 ÷ 6 = 14.
Sample mean x̅ = 14. - The sample mean is the central value around which the values in the sample are distributed. If the values in the sample cluster around the sample mean, then the variance is small; otherwise, the dispersion is large.
- In our example, add the values in the sample: 15 + 17 + 23 + 7 + 9 + 13 = 84
-
Subtract the sample mean from each value in the sample. Now calculate the difference x i (\displaystyle x_(i))- x̅, where x i (\displaystyle x_(i))- each value in the sample. Each result obtained indicates the extent to which a particular value deviates from the sample mean, that is, how far this value is from the sample mean.
- In our example:
x 1 (\displaystyle x_(1))- x̅ = 17 - 14 = 3
x 2 (\displaystyle x_(2))- x̅ = 15 - 14 = 1
x 3 (\displaystyle x_(3))- x̅ = 23 - 14 = 9
x 4 (\displaystyle x_(4))- x̅ = 7 - 14 = -7
x 5 (\displaystyle x_(5))- x̅ = 9 - 14 = -5
x 6 (\displaystyle x_(6))- x̅ = 13 - 14 = -1 - The correctness of the results obtained is easy to verify, since their sum must be equal to zero. This is related to the determination of the average value, since negative values (distances from the average value to smaller values) are completely offset by positive values (distances from the average value to larger values).
- In our example:
-
As noted above, the sum of the differences x i (\displaystyle x_(i))- x̅ must be equal to zero. This means that the mean variance is always zero, which does not give any idea of the spread of the values of some quantity. To solve this problem, square each difference x i (\displaystyle x_(i))- x̅. This will result in you only getting positive numbers which, when added together, will never add up to 0.
- In our example:
(x 1 (\displaystyle x_(1))-x̅) 2 = 3 2 = 9 (\displaystyle ^(2)=3^(2)=9)
(x 2 (\displaystyle (x_(2))-x̅) 2 = 1 2 = 1 (\displaystyle ^(2)=1^(2)=1)
9 2 = 81
(-7) 2 = 49
(-5) 2 = 25
(-1) 2 = 1 - You have found the square of the difference - x̅) 2 (\displaystyle ^(2)) for each value in the sample.
- In our example:
-
Calculate the sum of squared differences. That is, find the part of the formula that is written like this: ∑[( x i (\displaystyle x_(i))-x̅) 2 (\displaystyle ^(2))]. Here the sign Σ means the sum of squared differences for each value x i (\displaystyle x_(i)) in the sample. You have already found the squared differences (x i (\displaystyle (x_(i))-x̅) 2 (\displaystyle ^(2)) for each value x i (\displaystyle x_(i)) in the sample; now just add these squares.
- In our example: 9 + 1 + 81 + 49 + 25 + 1 = 166 .
-
Divide the result by n - 1, where n is the number of values in the sample. Some time ago, to calculate the sample variance, statisticians simply divided the result by n; in this case, you will get the mean of the squared variance, which is ideal for describing the variance of a given sample. But remember that any sample is only a small part of the general population of values. If you take a different sample and do the same calculations, you'll get a different result. As it turns out, dividing by n - 1 (rather than just n) gives a better estimate of the population variance, which is what you're after. Dividing by n - 1 has become commonplace, so it is included in the formula for calculating the sample variance.
- In our example, the sample includes 6 values, that is, n = 6.
Sample variance = s 2 = 166 6 − 1 = (\displaystyle s^(2)=(\frac (166)(6-1))=) 33,2
- In our example, the sample includes 6 values, that is, n = 6.
-
The difference between the variance and the standard deviation. Note that the formula contains an exponent, so the variance is measured in square units of the analyzed value. Sometimes such a value is quite difficult to operate; in such cases, the standard deviation is used, which is equal to the square root of the variance. That is why the sample variance is denoted as s 2 (\displaystyle s^(2)), and the sample standard deviation as s (\displaystyle s).
- In our example, the sample standard deviation is: s = √33.2 = 5.76.
Population variance calculation
-
Analyze some set of values. The set includes all values of the quantity under consideration. For example, if you are studying the age of residents of the Leningrad region, then the population includes the age of all residents of this region. In the case of working with an aggregate, it is recommended to create a table and enter the values of the aggregate into it. Consider the following example:
- There are 6 aquariums in a certain room. Each aquarium contains the following number of fish:
x 1 = 5 (\displaystyle x_(1)=5)
x 2 = 5 (\displaystyle x_(2)=5)
x 3 = 8 (\displaystyle x_(3)=8)
x 4 = 12 (\displaystyle x_(4)=12)
x 5 = 15 (\displaystyle x_(5)=15)
x 6 = 18 (\displaystyle x_(6)=18)
- There are 6 aquariums in a certain room. Each aquarium contains the following number of fish:
-
Write down the formula for calculating the population variance. Since the population includes all values of a certain quantity, the following formula allows you to get the exact value of the variance of the population. To distinguish population variance from sample variance (which is only an estimate), statisticians use various variables:
- σ 2 (\displaystyle ^(2)) = (∑(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n
- σ 2 (\displaystyle ^(2))- population variance (read as "sigma squared"). Dispersion is measured in square units.
- x i (\displaystyle x_(i))- each value in the aggregate.
- Σ is the sign of the sum. That is, for each value x i (\displaystyle x_(i)) subtract μ, square it, and then add the results.
- μ is the population mean.
- n is the number of values in the general population.
-
Calculate the population mean. When working with the general population, its average value is denoted as μ (mu). The population mean is calculated as the usual arithmetic mean: add up all the values in the population, and then divide the result by the number of values in the population.
- Keep in mind that averages are not always calculated as the arithmetic mean.
- In our example, the population mean: μ = 5 + 5 + 8 + 12 + 15 + 18 6 (\displaystyle (\frac (5+5+8+12+15+18)(6))) = 10,5
-
Subtract the population mean from each value in the population. The closer the difference value is to zero, the closer the particular value is to the population mean. Find the difference between each value in the population and its mean, and you'll get a first look at the distribution of the values.
- In our example:
x 1 (\displaystyle x_(1))- μ = 5 - 10.5 = -5.5
x 2 (\displaystyle x_(2))- μ = 5 - 10.5 = -5.5
x 3 (\displaystyle x_(3))- μ = 8 - 10.5 = -2.5
x 4 (\displaystyle x_(4))- μ = 12 - 10.5 = 1.5
x 5 (\displaystyle x_(5))- μ = 15 - 10.5 = 4.5
x 6 (\displaystyle x_(6))- μ = 18 - 10.5 = 7.5
- In our example:
-
Square each result you get. The difference values will be both positive and negative; if you put these values on a number line, then they will lie to the right and left of the population mean. This is not good for calculating variance, as positive and negative numbers cancel each other out. Therefore, square each difference to get exclusively positive numbers.
- In our example:
(x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2)) for each population value (from i = 1 to i = 6):
(-5,5)2 (\displaystyle ^(2)) = 30,25
(-5,5)2 (\displaystyle ^(2)), where x n (\displaystyle x_(n)) is the last value in the population. - To calculate the average value of the results obtained, you need to find their sum and divide it by n: (( x 1 (\displaystyle x_(1)) - μ) 2 (\displaystyle ^(2)) + (x 2 (\displaystyle x_(2)) - μ) 2 (\displaystyle ^(2)) + ... + (x n (\displaystyle x_(n)) - μ) 2 (\displaystyle ^(2))) / n
- Now let's write the above explanation using variables: (∑( x i (\displaystyle x_(i)) - μ) 2 (\displaystyle ^(2))) / n and obtain a formula for calculating the population variance.
- In our example:

