Least squares absolute errors. Least squares method in Excel
It is widely used in econometrics in the form of a clear economic interpretation of its parameters.
Linear regression is reduced to finding an equation of the form
or 
Equation of the form  allows for the given parameter values NS have the theoretical values of the effective indicator, substituting the actual values of the factor into it NS.
allows for the given parameter values NS have the theoretical values of the effective indicator, substituting the actual values of the factor into it NS.
Building linear regression is reduced to an assessment of its parameters - but and in. Estimates of the parameters of linear regression can be found by different methods.
The classical approach to estimating linear regression parameters is based on method least squares (OLS).
OLS allows one to obtain such parameter estimates but and in, at which the sum of the squares of the deviations of the actual values of the resultant attribute (y) from calculated (theoretical) minimal:

To find the minimum of the function, it is necessary to calculate the partial derivatives with respect to each of the parameters but and b and set them to zero.
We denote  through S, then:
through S, then:

Transforming the formula, we obtain the following system of normal equations for estimating the parameters but and in:

Solving the system of normal equations (3.5) either by the method successive elimination variables, or by the method of determinants, we find the required estimates of the parameters but and in.
Parameter in called the regression coefficient. Its value shows the average change in the result with a change in the factor by one unit.
The regression equation is always supplemented by an indicator of the tightness of the relationship. When linear regression is used, the linear correlation coefficient acts as such an indicator. There are different modifications of the formula linear coefficient correlation. Some of them are listed below:

As you know, the linear correlation coefficient is in the range: -1 ≤ ≤ 1.
To assess the quality of the selection of a linear function, the square is calculated
Linear correlation coefficient called the coefficient of determination. The coefficient of determination characterizes the proportion of the variance of the effective indicator y, explained by regression, in total variance effective attribute:

Accordingly, the value 1 - characterizes the proportion of dispersion y, caused by the influence of other factors not taken into account in the model.
Questions for self-control
1. What is the essence of the least squares method?
2. How many variables are paired regression provided?
3. What is the coefficient that determines the tightness of the relationship between changes?
4. Within what limits is the coefficient of determination determined?
5. Estimation of the parameter b in the correlation-regression analysis?
1. Christopher Dougherty. Introduction to Econometrics. - M .: INFRA - M, 2001 - 402 p.
2.S.A. Borodich. Econometrics. Minsk LLC "New Knowledge" 2001.
3. R.U. Rakhmetova A short course in econometrics. Tutorial... Almaty. 2004. -78s.
4. I.I. Eliseeva, Econometrics. - M .: "Finance and Statistics", 2002
5. Monthly information and analytical magazine.
Nonlinear economic models. Non-linear regression models. Conversion of variables.
Nonlinear economic models.
Conversion of variables.
Elasticity coefficient.
If there are non-linear relations between economic phenomena, then they are expressed using the corresponding non-linear functions: for example, an equilateral hyperbola  ,
parabolas of the second degree
,
parabolas of the second degree  and etc.
and etc.
There are two classes of nonlinear regressions:
1. Regressions that are nonlinear with respect to the explanatory variables included in the analysis, but linear with respect to the estimated parameters, for example:
Polynomials various degrees - ![]() , ;
, ;
Equilateral hyperbola -;
Semi-logarithmic function -.
2. Regressions that are non-linear in the parameters being estimated, for example:
Power -;
Indicative -;
Exponential -.
The total sum of the squares of the deviations of the individual values of the effective trait at from the average value due to the influence of many reasons. Let's conditionally divide the whole set of reasons into two groups: studied factor x and other factors.
If the factor does not affect the result, then the regression line on the graph is parallel to the axis Oh and 
Then the entire variance of the effective trait is due to the influence of other factors and the total sum of the squares of the deviations will coincide with the residual. If other factors do not affect the result, then u tied with NS functionally and the residual sum of squares is zero. In this case, the sum of squares of the deviations explained by the regression is the same as the total sum of squares.
Since not all points of the correlation field lie on the regression line, then their scatter always takes place as due to the influence of the factor NS, i.e., regression at on NS, and other causes (unexplained variation). The suitability of the regression line for forecasting depends on how much of the total variation of the characteristic at falls on the explained variation
Obviously, if the sum of squares of deviations due to the regression is greater than the residual sum of squares, then the regression equation is statistically significant and the factor NS has a significant impact on the result at.
, that is, with the number of freedom of independent variation of the feature. The number of degrees of freedom is associated with the number of units of the population n and with the number of constants determined from it. In relation to the problem under study, the number of degrees of freedom should show how many independent deviations from NS
The estimation of the significance of the regression equation as a whole is given with the help of F-Fisher's criterion. At the same time, a null hypothesis is put forward that the regression coefficient is zero, i.e. b = 0, and hence the factor NS does not affect the result at.
The direct calculation of the F-criterion is preceded by the analysis of variance. The central place in it is occupied by the decomposition of the total sum of the squares of the deviations of the variable at from the average at into two parts - "explained" and "unexplained":
 - the total sum of the squares of the deviations;
- the total sum of the squares of the deviations;
 - the sum of squares of the deviation explained by the regression;
- the sum of squares of the deviation explained by the regression;
 - residual sum of squares of deviation.
- residual sum of squares of deviation.
Any sum of squares of deviations is related to the number of degrees of freedom , that is, with the number of freedom of independent variation of the feature. The number of degrees of freedom is related to the number of population units n and with the number of constants determined from it. In relation to the problem under study, the number of degrees of freedom should show how many independent deviations from NS possible is required to form a given sum of squares.
Dispersion per degree of freedomD.
F-ratios (F-criterion): 

If the null hypothesis is true, then the factorial and residual variances do not differ from each other. For Н 0, a refutation is necessary so that the factorial variance exceeds the residual by several times. English statistician Snedecor developed tables critical values F-relations at different levels of significance of the null hypothesis and various numbers degrees of freedom. Table value F-criterion is the maximum value of the ratio of variances that can occur in case of their random discrepancy for a given level of probability of the presence of a null hypothesis. Calculated value F-relationship is recognized as reliable if it is more than tabular.
In this case, the null hypothesis of the absence of a connection between signs is rejected and a conclusion is made about the significance of this connection: F fact> F tab H 0 is rejected.
If the value is less than the table F fact ‹, F tab, then the probability of the null hypothesis is higher than a given level and it cannot be rejected without serious risk of making an incorrect conclusion about the presence of a connection. In this case, the regression equation is considered statistically insignificant. But it does not deviate.
Regression coefficient standard error
To assess the significance of the regression coefficient, its value is compared with its standard error, i.e., the actual value is determined t- Student's criterion:  which is then compared with table value at a certain level of significance and the number of degrees of freedom ( n- 2).
which is then compared with table value at a certain level of significance and the number of degrees of freedom ( n- 2).
Parameter standard error but:

The significance of the linear correlation coefficient is checked based on the magnitude of the error correlation coefficient t r:


Total variance of a trait NS: 
Multiple Linear Regression
Building the model
Multiple regression is a regression of the effective trait with two and a large number factors, i.e. a model of the form

Regression can give a good result in modeling, if the influence of other factors affecting the research object can be neglected. The behavior of individual economic variables cannot be controlled, that is, it is not possible to ensure the equality of all other conditions for assessing the influence of one investigated factor. In this case, one should try to identify the influence of other factors by introducing them into the model, i.e., construct the equation multiple regression: y = a + b 1 x 1 + b 2 +… + b p x p + .
The main goal of multiple regression is to build a model with a large number of factors, while determining the influence of each of them separately, as well as their cumulative effect on the modeled indicator. Model specification includes two areas of issues: selection of factors and selection of the type of regression equation
Least square method is used to estimate the parameters of the regression equation.One of the methods for studying stochastic relationships between features is regression analysis.
Regression analysis is the derivation of the regression equation, which is used to find average value a random variable (feature-result), if the value of another (or other) variables (feature-factors) is known. It includes the following steps:
- choice of the form of communication (type analytical equation regression);
- estimation of the parameters of the equation;
- assessment of the quality of the analytical regression equation.
In the case of a linear pairwise connection, the regression equation will take the form: y i = a + b x i + u i. Parameters this equation a and b are estimated from the data of statistical observation x and y. The result of such an assessment is the equation:, where, are the estimates of the parameters a and b, is the value of the effective attribute (variable) obtained by the regression equation (calculated value).
Most often, parameters are estimated using least squares method (OLS).
The least squares method gives the best (consistent, efficient and unbiased) estimates of the parameters of the regression equation. But only if certain prerequisites for the random term (u) and the independent variable (x) are met (see OLS prerequisites).
The problem of estimating the parameters of a linear paired equation by the least squares method consists in the following: to obtain such parameter estimates, at which the sum of the squares of the deviations of the actual values of the effective indicator - y i from the calculated values - is minimal.
Formally OLS criterion can be written like this:  .
.
Classification of least squares methods
- Least square method.
- Maximum likelihood method (for the normal classical linear regression model, the normality of the regression residuals is postulated).
- The generalized least squares OLS method is used in the case of autocorrelation of errors and in the case of heteroscedasticity.
- Weighted least squares method (a special case of OLS with heteroscedastic residuals).
Let's illustrate the essence classical method least squares graphically... To do this, we will build a dot plot according to the observation data (x i, y i, i = 1; n) in a rectangular coordinate system (such a dot plot is called the correlation field). Let's try to find a straight line that is closest to the points of the correlation field. According to the method of least squares, the line is chosen so that the sum of the squares of the vertical distances between the points of the correlation field and this line would be minimal. 
Mathematical record of this problem:  .
.
We know the values of y i and x i = 1 ... n, these are observational data. In the S function, they are constants. The variables in this function are the required parameter estimates -,. To find the minimum of a function of 2 variables, it is necessary to calculate the partial derivatives of this function for each of the parameters and equate them to zero, i.e. 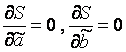 .
.
As a result, we get a system of 2 normal linear equations: 
Solving this system, we find the required parameter estimates: 
The correctness of the calculation of the parameters of the regression equation can be checked by comparing the sums (there may be some discrepancy due to rounding of calculations).
To calculate the parameter estimates, you can build table 1.
The sign of the regression coefficient b indicates the direction of the relationship (if b> 0, the relationship is direct, if b<0, то связь обратная). Величина b показывает на сколько единиц изменится в среднем признак-результат -y при изменении признака-фактора - х на 1 единицу своего измерения.
Formally, the value of parameter a is the average value of y at x equal to zero. If the attribute factor does not and cannot have a zero value, then the above interpretation of the parameter a does not make sense.
Assessment of the tightness of the relationship between the signs
is carried out using the coefficient of linear pair correlation - r x, y. It can be calculated using the formula:  ... In addition, the linear pairwise correlation coefficient can be determined through the regression coefficient b:
... In addition, the linear pairwise correlation coefficient can be determined through the regression coefficient b:  .
.
The range of admissible values of the linear pair correlation coefficient is from –1 to +1. The sign of the correlation coefficient indicates the direction of the link. If r x, y> 0, then the connection is direct; if r x, y<0, то связь обратная.
If this coefficient is close to one in modulus, then the relationship between the features can be interpreted as a rather close linear one. If its modulus is equal to one ê r x, y ê = 1, then the connection between the features is functional linear. If features x and y are linearly independent, then r x, y is close to 0.
To calculate r x, y, you can also use table 1.
Table 1
| N observation | x i | y i | x i ∙ y i | ||
| 1 | x 1 | y 1 | x 1 y 1 | ||
| 2 | x 2 | y 2 | x 2 y 2 | ||
| ... | |||||
| n | x n | y n | x n y n | ||
| Column sum | ∑x | ∑y | ∑x y | ||
| Average value |
|
|
 ,
,
where d 2 is the variance y explained by the regression equation;
e 2 - residual (not explained by the regression equation) variance y;
s 2 y is the total (total) variance of y.
The coefficient of determination characterizes the proportion of the variation (variance) of the effective trait y, explained by regression (and, consequently, by the factor x), in the total variation (variance) y. The coefficient of determination R 2 yx takes values from 0 to 1. Accordingly, the value 1-R 2 yx characterizes the proportion of variance y caused by the influence of other factors not taken into account in the model and specification errors.
With paired linear regression R 2 yx = r 2 yx.
Example.
Experimental data on the values of variables NS and at are given in the table.
As a result of their alignment, the function ![]()
Using least square method, approximate this data with a linear dependence y = ax + b(find parameters but and b). Find out which of the two lines is better (in the sense of the least squares method) aligns the experimental data. Make a drawing.
The essence of the least squares method (mns).
The task is to find the coefficients of the linear dependence for which the function of two variables but and b
![]() takes the smallest value. That is, given but and b the sum of the squares of the deviations of the experimental data from the found straight line will be the smallest. This is the whole point of the least squares method.
takes the smallest value. That is, given but and b the sum of the squares of the deviations of the experimental data from the found straight line will be the smallest. This is the whole point of the least squares method.
Thus, the solution of the example is reduced to finding the extremum of a function of two variables.
Derivation of formulas for finding coefficients.
A system of two equations with two unknowns is composed and solved. Find the partial derivatives of the function ![]() by variables but and b, we equate these derivatives to zero.
by variables but and b, we equate these derivatives to zero. 
We solve the resulting system of equations by any method (for example substitution method or Cramer's method) and obtain formulas for finding the coefficients using the least squares method (OLS). 
With data but and b function ![]() takes the smallest value. The proof of this fact is given below in the text at the end of the page.
takes the smallest value. The proof of this fact is given below in the text at the end of the page.
That's the whole least squares method. Formula for finding the parameter a contains the sums ,,, and the parameter n- the amount of experimental data. We recommend calculating the values of these amounts separately. Coefficient b is after calculation a.
It's time to remember the original example.
Solution.
In our example n = 5... We fill in the table for the convenience of calculating the amounts that are included in the formulas of the desired coefficients. 
The values in the fourth row of the table are obtained by multiplying the values of the 2nd row by the values of the 3rd row for each number i.
The values in the fifth row of the table are obtained by squaring the values of the 2nd row for each number i.
The values of the last column of the table are the sums of the values by row.
We use the formulas of the least squares method to find the coefficients but and b... We substitute in them the corresponding values from the last column of the table: 
Consequently, y = 0.165x + 2.184 is the required approximating straight line.
It remains to find out which of the lines y = 0.165x + 2.184 or ![]() better approximates the original data, that is, make an estimate using the least squares method.
better approximates the original data, that is, make an estimate using the least squares method.
Estimation of the error of the least squares method.
To do this, you need to calculate the sum of the squares of the deviations of the initial data from these lines ![]() and
and ![]() , a smaller value corresponds to a line that better approximates the original data in the sense of the least squares method.
, a smaller value corresponds to a line that better approximates the original data in the sense of the least squares method. 
Since then straight y = 0.165x + 2.184 approximates the original data better.
Graphical illustration of the method of least squares (mns).
Everything is perfectly visible on the graphs. The red line is the straight line found y = 0.165x + 2.184, the blue line is ![]() , pink dots are raw data.
, pink dots are raw data.

In practice, when modeling various processes - in particular, economic, physical, technical, social - one or another method of calculating the approximate values of functions from their known values at some fixed points is widely used.
Such problems of approximating functions often arise:
when constructing approximate formulas for calculating the values of the characteristic values of the process under study according to tabular data obtained as a result of the experiment;
for numerical integration, differentiation, solving differential equations, etc .;
when it is necessary to calculate the values of functions at intermediate points of the considered interval;
when determining the values of the characteristic quantities of the process outside the considered interval, in particular when predicting.
If, to model a certain process given by the table, construct a function that approximately describes this process based on the least squares method, it will be called an approximating function (regression), and the problem of constructing approximating functions itself is an approximation problem.
This article discusses the capabilities of the MS Excel package for solving such problems, in addition, methods and techniques for constructing (creating) regressions for table-defined functions (which is the basis of regression analysis) are given.
Excel has two options for plotting regressions.
Adding the selected regressions (trend lines - trendlines) to the diagram, built on the basis of the data table for the investigated process characteristic (available only if there is a constructed diagram);
Using the built-in statistical functions of an Excel worksheet to obtain regressions (trend lines) directly from the source data table.
Adding trend lines to a chart
For a table of data describing a certain process and represented by a diagram, Excel has an effective regression analysis tool that allows you to:
build on the basis of the least squares method and add five types of regressions to the diagram, which model the process under study with varying degrees of accuracy;
add the equation of the constructed regression to the diagram;
determine the degree to which the selected regression matches the data displayed on the chart.
Based on the data of the Excel chart, it allows you to obtain linear, polynomial, logarithmic, exponential, exponential types of regressions, which are given by the equation:
y = y (x)
where x is an independent variable, which often takes on the values of a sequence of natural numbers (1; 2; 3; ...) and produces, for example, the countdown of the running time of the process under study (characteristics).
1 ... Linear regression is good for modeling characteristics that increase or decrease at a constant rate. This is the simplest model of the process under study to construct. It is built according to the equation:
y = mx + b
where m is the tangent of the angle of inclination of the linear regression to the abscissa axis; b - coordinate of the point of intersection of linear regression with the ordinate axis.
2 ... The polynomial trendline is useful for describing characteristics that have several distinct extremes (highs and lows). The choice of the degree of the polynomial is determined by the number of extrema of the studied characteristic. Thus, a polynomial of the second degree can describe well a process that has only one maximum or minimum; polynomial of the third degree - no more than two extrema; polynomial of the fourth degree - no more than three extrema, etc.
In this case, the trend line is plotted according to the equation:
y = c0 + c1x + c2x2 + c3x3 + c4x4 + c5x5 + c6x6
where the coefficients c0, c1, c2, ... c6 are constants whose values are determined during construction.
3 ... The logarithmic trend line is successfully used to simulate characteristics, the values of which change rapidly at first, and then gradually stabilize.
y = c ln (x) + b
4 ... A power-law trend line gives good results if the values of the studied dependence are characterized by a constant change in the growth rate. An example of such a dependence is a graph of uniformly accelerated movement of a car. If the data contains zero or negative values, you cannot use a power trendline.
It is built in accordance with the equation:
y = c xb
where the coefficients b, c are constants.
5 ... An exponential trendline should be used when the rate of change in data is continuously increasing. For data containing zero or negative values, this kind of approximation is also not applicable.
It is built in accordance with the equation:
y = c ebx
where the coefficients b, c are constants.
When selecting a trend line, Excel automatically calculates the value of R2, which characterizes the accuracy of the approximation: the closer the value of R2 is to one, the more reliably the trend line approximates the process under study. If necessary, the R2 value can always be displayed on the chart.
Determined by the formula:

To add a trend line to a data series:
activate a chart based on a series of data, that is, click within the chart area. The Chart item will appear in the main menu;
after clicking on this item, a menu will appear on the screen, in which you should select the Add trend line command.
The same actions are easily accomplished by hovering the mouse pointer over the graph corresponding to one of the data series and clicking the right mouse button; in the context menu that appears, select the Add trend line command. The Trendline dialog box with the Type tab expanded (Fig. 1) will appear on the screen.

After that it is necessary:
Select the required trendline type on the Type tab (by default, the Linear type is selected). For the Polynomial type, in the Degree field, specify the degree of the selected polynomial.
1 ... The Plotted on Series box lists all the data series of the chart in question. To add a trend line to a specific data series, select its name in the Plotted on Series field.

If necessary, by going to the Parameters tab (Fig. 2), you can set the following parameters for the trend line:
change the name of the trend line in the Name of the approximating (smoothed) curve field.
set the number of periods (forward or backward) for the forecast in the Forecast field;
display the equation of the trend line in the chart area, for which you should enable the Show equation on the chart checkbox;
display the value of the approximation reliability R2 in the diagram area, for which you should enable the checkbox to place the approximation reliability value (R ^ 2) on the diagram;
set the point of intersection of the trend line with the Y axis, for which you should enable the intersection of the curve with the Y axis at a point checkbox;
click on the OK button to close the dialog box.
In order to start editing an already built trend line, there are three ways:
use the Selected trend line command from the Format menu, having previously selected the trend line;
select the Format trendline command from the context menu, which is invoked by right-clicking on the trend line;
by double clicking on the trend line.
The Trendline Format dialog box (Fig. 3) will appear on the screen, containing three tabs: View, Type, Parameters, and the contents of the latter two completely coincide with similar tabs in the Trendline dialog box (Fig. 1-2). On the View tab, you can set the line type, its color and thickness.

To delete an already built trend line, select the trend line to be deleted and press the Delete key.
The advantages of the considered regression analysis tool are:
the relative ease of plotting a trend line on charts without creating a data table for it;
a fairly wide list of types of proposed trend lines, and this list includes the most commonly used types of regression;
the ability to predict the behavior of the process under study for an arbitrary (within common sense) number of steps forward, as well as backward;
the ability to obtain the equation of the trend line in an analytical form;
the possibility, if necessary, of obtaining an estimate of the reliability of the approximation carried out.
The disadvantages include the following points:
the construction of a trend line is carried out only if there is a diagram built on a number of data;
the process of forming data series for the studied characteristic based on the trend line equations obtained for it is somewhat cluttered: the sought regression equations are updated with each change in the values of the original data series, but only within the diagram area, while the data series formed on the basis of the old line equation trend remains unchanged;
In PivotChart reports, when you change the view of a chart or a linked PivotTable report, existing trendlines are not retained, that is, before you draw trendlines or otherwise format the PivotChart report, you must ensure that the report layout meets your requirements.
Trend lines can be used to supplement data series presented on charts such as graph, bar, flat unnormalized area charts, bar, scatter, bubble, and stock charts.
You cannot add trendlines to data series in 3-D, Normalized, Radar, Pie, and Donut charts.
Using built-in Excel functions
Excel also provides a regression analysis tool for plotting trend lines outside the chart area. A number of worksheet statistical functions can be used for this purpose, but all of them allow only linear or exponential regressions to be built.
Excel provides several functions for constructing linear regression, in particular:
INCLINE and INTERCEPT.
TREND;
And also several functions for building an exponential trendline, in particular:
LGRFPRIBL.
It should be noted that the methods of constructing regressions using the TREND and GROWTH functions practically coincide. The same can be said for a pair of LINEST and LGRFPRIBL functions. For these four functions, Excel features such as array formulas are used to create a table of values, which makes the regression process somewhat cluttered. Note also that the construction of linear regression, in our opinion, is easiest to carry out using the SLOPE and INTERCEPT functions, where the first of them determines the slope of linear regression, and the second is the segment cut off by the regression on the ordinate axis.
The benefits of the built-in regression analysis tool include:
a fairly simple process of the same type of formation of data series of the studied characteristic for all built-in statistical functions that set trend lines;
standard technique for constructing trend lines based on generated data series;
the ability to predict the behavior of the process under study for the required number of steps forward or backward.
The disadvantage is that Excel does not have built-in functions for creating other (besides linear and exponential) trendline types. This circumstance often does not allow choosing a sufficiently accurate model of the process under study, as well as obtaining forecasts that are close to reality. Also, when using the TREND and GROWTH functions, the trend line equations are not known.
It should be noted that the authors did not set the goal of the article to present the course of regression analysis with varying degrees of completeness. Its main task is to show the capabilities of the Excel package in solving approximation problems using specific examples; demonstrate what effective tools Excel has for building regressions and forecasting; illustrate how relatively easily such problems can be solved even by a user who does not have deep knowledge of regression analysis.
Examples of solving specific problems
Let's consider the solution of specific tasks using the listed tools of the Excel package.
Problem 1
With a table of data on the profit of a trucking company for 1995-2002. you need to do the following.
Build a diagram.
Add linear and polynomial (quadratic and cubic) trend lines to the chart.
Using the trend line equations, obtain tabular data on enterprise profits for each trend line for 1995-2004.
Make a forecast for the profit of the enterprise for 2003 and 2004.
The solution of the problem

In the range of cells A4: C11 of the Excel worksheet, enter the worksheet shown in Fig. 4.
Having selected the range of cells B4: C11, we build a diagram.
We activate the constructed chart and, according to the method described above, after selecting the type of trend line in the Trendline dialog box (see Fig. 1), add linear, quadratic and cubic trend lines to the chart in turn. In the same dialog box, open the Parameters tab (see Fig. 2), in the Name of the approximating (smoothed) curve field, enter the name of the added trend, and in the Forecast forward for: periods field, set the value 2, since it is planned to make a profit forecast for two years ahead. To display the regression equation and the approximation reliability value R2 in the diagram area, turn on the checkboxes to show the equation on the screen and place the approximation reliability value (R ^ 2) on the diagram. For a better visual perception, we change the type, color and thickness of the constructed trend lines, for which we use the View tab of the Trendline Format dialog box (see Fig. 3). The resulting diagram with added trend lines is shown in Fig. five.
To obtain tabular data on the profit of the enterprise for each trend line for 1995-2004. Let us use the trend line equations shown in Fig. 5. To do this, in the cells of the range D3: F3, enter text information about the type of the selected trend line: Linear trend, Quadratic trend, Cubic trend. Next, enter the linear regression formula in cell D4 and, using the fill marker, copy this formula with relative references to the range of cells D5: D13. It should be noted that each cell with a linear regression formula from the range of cells D4: D13 takes the corresponding cell from the range A4: A13 as an argument. Similarly, for quadratic regression, the cell range E4: E13 is filled, and for cubic regression, the cell range F4: F13 is filled. Thus, the forecast for the profit of the enterprise for 2003 and 2004 was made. using three trends. The resulting table of values is shown in Fig. 6.


Task 2
Build a diagram.
Add logarithmic, exponential and exponential trend lines to the chart.
Derive the equations of the obtained trend lines, as well as the values of the approximation reliability R2 for each of them.
Using the trend line equations, obtain tabular data on enterprise profits for each trend line for 1995-2002.
Make a forecast of the company's profit for 2003 and 2004 using these trend lines.
The solution of the problem
Following the methodology given in solving Problem 1, we obtain a diagram with added logarithmic, power and exponential trend lines (Fig. 7). Further, using the obtained equations of the trend lines, we fill in the table of values for the profit of the enterprise, including the predicted values for 2003 and 2004. (fig. 8).


In fig. 5 and fig. it can be seen that the model with a logarithmic trend corresponds to the smallest value of the approximation reliability
R2 = 0.8659
The largest values of R2 correspond to models with a polynomial trend: quadratic (R2 = 0.9263) and cubic (R2 = 0.933).
Problem 3
With the table of data on the profit of a trucking company for 1995-2002, given in task 1, you must perform the following actions.
Get data series for linear and exponential trendlines using TREND and GROWTH functions.
Using the TREND and GROWTH functions, make a forecast of the company's profit for 2003 and 2004.
Build a diagram for the initial data and the resulting data series.
The solution of the problem
Let's use the worksheet of task 1 (see Fig. 4). Let's start with the TREND function:
select the range of cells D4: D11, which should be filled with the values of the TREND function, corresponding to the known data on the profit of the enterprise;
call the Function command from the Insert menu. In the Function Wizard dialog box that appears, select the TREND function from the Statistical category, and then click on the OK button. The same operation can be performed by pressing the (Insert function) button on the standard toolbar.
In the Function Arguments dialog box that appears, enter the range of cells C4: C11 in the Known_values_y field; in the Known_x's field - the range of cells B4: B11;
to make the entered formula an array formula, use the + + key combination.
The formula we entered in the formula bar will look like: = (TREND (C4: C11; B4: B11)).
As a result, the range of cells D4: D11 is filled with the corresponding values of the TREND function (Fig. 9).

To make a forecast of the company's profit for 2003 and 2004. necessary:
select the range of cells D12: D13, where the values predicted by the TREND function will be entered.
call the TREND function and in the Function Arguments dialog box that appears, enter in the Known_values_y field - the range of cells C4: C11; in the Known_x's field - the range of cells B4: B11; and the New_x_values field contains the range of cells B12: B13.
turn this formula into an array formula using the keyboard shortcut Ctrl + Shift + Enter.
The entered formula will look like: = (TREND (C4: C11; B4: B11; B12: B13)), and the range of cells D12: D13 will be filled with the predicted values of the TREND function (see Fig. 9).
Similarly, a data series is filled using the GROWTH function, which is used in the analysis of nonlinear dependencies and works in exactly the same way as its linear analogue TREND.
Figure 10 shows the table in the formulas display mode.


For the initial data and the obtained data series, the diagram shown in Fig. eleven.
Problem 4
With the table of data on the receipt of applications for services by the dispatch service of the motor transport company for the period from the 1st to the 11th day of the current month, you must perform the following actions.
Get data series for linear regression: using the SLOPE and INTERCEPT functions; using the LINEST function.
Get a data series for exponential regression using the LGRFPRIBL function.
Using the above functions, make a forecast about the receipt of applications in the dispatch service for the period from the 12th to the 14th day of the current month.
Build a diagram for the original and received data series.
The solution of the problem
Note that, unlike the TREND and GROWTH functions, none of the above functions (SLOPE, INTERCEPT, LINEST, LGRFPRIB) is a regression. These functions play only an auxiliary role, defining the necessary parameters of the regression.
For linear and exponential regressions built using the SLOPE, INTERCEPT, LINEST, LGRFPRIB functions, the appearance of their equations is always known, in contrast to the linear and exponential regressions corresponding to the TREND and GROWTH functions.
1 ... Let's construct a linear regression with the equation:
y = mx + b
with the TILT and INTERCEPT functions, whereby slope In the regression, m is defined by the SLOPE function, and the intercept b by the INTERCEPT function.
To do this, we carry out the following actions:
we enter the original table into the range of cells A4: B14;
the value of parameter m will be determined in cell C19. Select from the Statistical category Slope; enter the range of cells B4: B14 in the known_y's field and the range of cells A4: A14 in the known_x's field. The formula will be entered into cell C19: = SLOPE (B4: B14; A4: A14);
the value of parameter b in cell D19 is determined in a similar manner. And its content will look like: = INTERCEPT (B4: B14; A4: A14). Thus, the values of the parameters m and b necessary for constructing the linear regression will be stored in cells C19, D19, respectively;
then we enter the linear regression formula in cell C4 in the form: = $ C * A4 + $ D. In this formula, cells C19 and D19 are written with absolute references (the cell address should not change when copying is possible). The absolute reference sign $ can be typed either from the keyboard or by using the F4 key, after placing the cursor on the cell address. Using the fill marker, copy this formula to the range of cells C4: C17. We get the required data series (Fig. 12). Due to the fact that the number of orders is an integer, you should set the number format with 0 decimal places on the Number tab of the Format cells window.
2 ... Now let's build a linear regression given by the equation:
y = mx + b
using the LINEST function.
For this:
enter the LINEST function into the range of cells C20: D20 as an array formula: = (LINEST (B4: B14; A4: A14)). As a result, we get in cell C20 the value of parameter m, and in cell D20 - the value of parameter b;
enter the formula in cell D4: = $ C * A4 + $ D;
copy this formula using the fill handle to the range of cells D4: D17 and get the required data series.
3 ... We build an exponential regression that has the equation:
using the LGRFPRIBL function, it is performed in the same way:
into the range of cells C21: D21 we enter the LGRFPRIBL function as an array formula: = (LGRFPRIBL (B4: B14; A4: A14)). In this case, in cell C21 the value of the parameter m will be determined, and in cell D21 - the value of the parameter b;
the formula is entered into cell E4: = $ D * $ C ^ A4;
using the fill marker, this formula is copied to the range of cells E4: E17, where the data series for the exponential regression will be located (see Fig. 12).

In fig. 13 is a table where you can see the functions we use with the required ranges of cells, as well as formulas.
The quantity R 2 called coefficient of determination.
The task of constructing a regression dependence is to find the vector of coefficients m of the model (1) at which the coefficient R takes its maximum value.
To assess the significance of R, Fisher's F-test is used, calculated by the formula

where n- sample size (number of experiments);
k is the number of coefficients of the model.
If F exceeds some critical value for the data n and k and the accepted confidence level, then the value of R is considered significant. Tables of critical values of F are given in handbooks on mathematical statistics.
Thus, the significance of R is determined not only by its value, but also by the ratio between the number of experiments and the number of coefficients (parameters) of the model. Indeed, the correlation ratio for n = 2 for a simple linear model is 1 (through 2 points on the plane, you can always draw a single straight line). However, if the experimental data are random values, such R value should be trusted with great care. Usually, to obtain a significant R and reliable regression, one strives to ensure that the number of experiments significantly exceeds the number of model coefficients (n> k).
To build a linear regression model, you must:
1) prepare a list of n rows and m columns containing experimental data (a column containing the output value Y must be either first or last in the list); for example, we will take the data of the previous task, adding a column with the name "Period No.", we will number the period numbers from 1 to 12. (these will be the values NS)
2) go to the menu Data / Data Analysis / Regression

If the "Data Analysis" item in the "Tools" menu is absent, then you should go to the "Add-ins" item of the same menu and select the "Analysis package" checkbox.
3) in the "Regression" dialog box set:
· Input interval Y;
· Input interval X;
· Output interval - the upper left cell of the interval in which the results of calculations will be placed (it is recommended to place them on a new worksheet);

4) click "Ok" and analyze the results.
If some physical quantity depends on another quantity, then this dependence can be investigated by measuring y at different meanings x. As a result of measurements, a number of values are obtained:
x 1, x 2, ..., x i, ..., x n;
y 1, y 2, ..., y i, ..., y n.
Based on the data of such an experiment, it is possible to construct a graph of the dependence y = ƒ (x). The resulting curve makes it possible to judge the form of the function ƒ (x). but constant coefficients which are included in this function remain unknown. The method of least squares allows you to determine them. Experimental points, as a rule, do not fit exactly on the curve. The least squares method requires that the sum of the squared deviations of the experimental points from the curve, i.e. 2 was the smallest.
In practice, this method is most often (and most simply) used in the case of a linear relationship, i.e. when
y = kx or y = a + bx.
Linear dependence is very widespread in physics. And even when the dependence is non-linear, they usually try to plot the graph in such a way as to get a straight line. For example, if it is assumed that the refractive index of glass n is related to the length λ of the light wave by the ratio n = a + b / λ 2, then the dependence of n on λ -2 is plotted on the graph.
Consider the dependency y = kx(straight line passing through the origin). Let's compose the value φ - the sum of the squares of the deviations of our points from the straight line
The value of φ is always positive and turns out to be the smaller, the closer our points lie to the straight line. The least squares method states that for k one should choose such a value at which φ has a minimum
![]()
or
(19)
The calculation shows that the root-mean-square error in determining the value of k is equal to
 , (20)
, (20)
where - n is the number of measurements.
Let us now consider a somewhat more difficult case, when the points must satisfy the formula y = a + bx(straight line not passing through the origin).
The task is to find the best values of a and b from the available set of values x i, y i.
Again, we compose the quadratic form φ, equal to the sum of the squares of the deviations of the points x i, y i from the straight line
![]()
and find the values of a and b for which φ has a minimum
![]() ;
;
![]() .
.
The joint solution of these equations gives
![]() (21)
(21)
The root-mean-square errors in determining a and b are equal
 (23)
(23)
 ... & nbsp (24)
... & nbsp (24)
When processing measurement results by this method, it is convenient to summarize all data in a table, in which all the sums included in formulas (19) - (24) are preliminarily calculated. The forms of these tables are shown in the examples discussed below.
Example 1. The basic equation of the dynamics of rotational motion ε = M / J (a straight line passing through the origin of coordinates) was investigated. For different values of the moment M, the angular acceleration ε of a certain body was measured. It is required to determine the moment of inertia of this body. The results of measurements of the moment of force and angular acceleration are entered in the second and third columns. table 5.
Table 5
| n | M, Nm | ε, s -1 | M 2 | M ε | ε - kM | (ε - kM) 2 |
| 1 | 1.44 | 0.52 | 2.0736 | 0.7488 | 0.039432 | 0.001555 |
| 2 | 3.12 | 1.06 | 9.7344 | 3.3072 | 0.018768 | 0.000352 |
| 3 | 4.59 | 1.45 | 21.0681 | 6.6555 | -0.08181 | 0.006693 |
| 4 | 5.90 | 1.92 | 34.81 | 11.328 | -0.049 | 0.002401 |
| 5 | 7.45 | 2.56 | 55.5025 | 19.072 | 0.073725 | 0.005435 |
| ∑ | | | 123.1886 | 41.1115 | | 0.016436 |
By formula (19) we determine:
![]() .
.
To determine the mean square error, we use the formula (20)
0.005775Kg-one · m -2 .
By formula (18), we have

S J = (2.996 0.005775) /0.3337 = 0.05185 kg m 2.
Given the reliability P = 0.95, according to the table of Student's coefficients for n = 5, we find t = 2.78 and determine the absolute error ΔJ = 2.78 0.05185 = 0.1441 ≈ 0.2 kg m 2.
We will write the results in the form:
J = (3.0 ± 0.2) kg m 2;
Example 2. Let's calculate the temperature coefficient of resistance of the metal using the least squares method. Resistance is linear with temperature
R t = R 0 (1 + α t °) = R 0 + R 0 α t °.
The free term defines the resistance R 0 at 0 ° C, and the slope is the product of the temperature coefficient α and the resistance R 0.
The results of measurements and calculations are shown in the table ( see table 6).
Table 6
| n | t °, s | r, Ohm | t-¯ t | (t-¯ t) 2 | (t-¯ t) r | r - bt - a | (r - bt - a) 2, 10 -6 |
| 1 | 23 | 1.242 | -62.8333 | 3948.028 | -78.039 | 0.007673 | 58.8722 |
| 2 | 59 | 1.326 | -26.8333 | 720.0278 | -35.581 | -0.00353 | 12.4959 |
| 3 | 84 | 1.386 | -1.83333 | 3.361111 | -2.541 | -0.00965 | 93.1506 |
| 4 | 96 | 1.417 | 10.16667 | 103.3611 | 14.40617 | -0.01039 | 107.898 |
| 5 | 120 | 1.512 | 34.16667 | 1167.361 | 51.66 | 0.021141 | 446.932 |
| 6 | 133 | 1.520 | 47.16667 | 2224.694 | 71.69333 | -0.00524 | 27.4556 |
| ∑ | 515 | 8.403 | | 8166.833 | 21.5985 | | 746.804 |
| ∑ / n | 85.83333 | 1.4005 | | | | | |
Using formulas (21), (22), we determine
R 0 = ¯ R- α R 0 ¯ t = 1.4005 - 0.002645 85.83333 = 1.1735 Ohm.
Let us find the error in the definition of α. Since, then by formula (18) we have:
 .
.
Using formulas (23), (24), we have

 ;
;
0.014126 Ohm.
Given the reliability P = 0.95, according to the table of Student's coefficients for n = 6, we find t = 2.57 and determine the absolute error Δα = 2.57 0.000132 = 0.000338 deg -1.
α = (23 ± 4) · 10 -4 hail-1 at P = 0.95.
Example 3. It is required to determine the radius of curvature of the lens using Newton's rings. The radii of Newton's rings r m were measured and the numbers of these rings m were determined. The radii of Newton's rings are related to the radius of curvature of the lens R and the number of the ring by the equation
r 2 m = mλR - 2d 0 R,
where d 0 is the thickness of the gap between the lens and the plane-parallel plate (or lens deformation),
λ is the wavelength of the incident light.
λ = (600 ± 6) nm;
r 2 m = y;
m = x;
λR = b;
-2d 0 R = a,
then the equation takes the form y = a + bx.
.The results of measurements and calculations are recorded in Table 7.
Table 7
| n | x = m | y = r 2, 10 -2 mm 2 | m -¯ m | (m -¯ m) 2 | (m -¯ m) y | y - bx - a, 10 -4 | (y - bx - a) 2, 10 -6 |
| 1 | 1 | 6.101 | -2.5 | 6.25 | -0.152525 | 12.01 | 1.44229 |
| 2 | 2 | 11.834 | -1.5 | 2.25 | -0.17751 | -9.6 | 0.930766 |
| 3 | 3 | 17.808 | -0.5 | 0.25 | -0.08904 | -7.2 | 0.519086 |
| 4 | 4 | 23.814 | 0.5 | 0.25 | 0.11907 | -1.6 | 0.0243955 |
| 5 | 5 | 29.812 | 1.5 | 2.25 | 0.44718 | 3.28 | 0.107646 |
| 6 | 6 | 35.760 | 2.5 | 6.25 | 0.894 | 3.12 | 0.0975819 |
| ∑ | 21 | 125.129 | | 17.5 | 1.041175 | | 3.12176 |
| ∑ / n | 3.5 | 20.8548333 | | | | | |