If the partial coefficient of determination is a negative number. Calculation of the coefficient of determination in Microsoft Excel
Variation of a feature determined various factors, some of these factors can be distinguished if the statistical population is divided into groups according to a certain criterion. Then, along with the study of the variation of the trait in the population as a whole, it is possible to study the variation for each of its constituent groups and between these groups. In the simple case, when the population is divided into groups according to one factor, the study of variation is achieved by calculating and analyzing three types of variance: total, intergroup and intragroup.
Empirical coefficient of determination
Empirical coefficient of determination widely used in statistical analysis and is an indicator representing the proportion of intergroup variance in the effective trait and characterizes the strength of the influence of the grouping trait on the formation of general variation. It can be calculated using the formula:
Shows the proportion of variation of the effective attribute y under the influence of the factor attribute x, it is associated with the correlation coefficient by a quadratic dependence. In the absence of communication, the empirical coefficient of determination is zero, and at functional communication- unit.
For example, when the dependence of labor productivity of workers on their qualifications is studied, the coefficient of determination is 0.7, then 70% of the variation in labor productivity of workers is due to differences in their qualifications and 30% is due to the influence of other factors.
The empirical correlation is the square root of the coefficient of determination. The ratio shows the closeness of the relationship between the grouping and the productive characteristics. The empirical correlation ratio takes values from -1 to 1. If there is no connection, then the correlation ratio is equal to zero, i.e. all group means are equal to each other and there is no intergroup variation. This means that the grouping trait does not affect the formation of the general variation.
If the connection is functional, then the correlation ratio is equal to one. In this case, the variance of the group means is equal to the total variance, i.e. there is no intra-group variation. This means that the grouping characteristic completely determines the variation of the effective characteristic.
How closer meaning the correlation ratio to one, the stronger and closer to the functional dependence the relationship between the signs. For a qualitative assessment of the strength of the connection based on the indicator of the empirical correlation coefficient, you can use the Chaddock ratio.
Chaddock ratio
- The connection is very close - the correlation coefficient is in the range 0.9 - 0.99
- Close connection - Rxy = 0.7 - 0.9
- The connection is noticeable - Rxy = 0.5 - 0.7
- Moderate relationship - Rxy = 0.3 - 0.5
- The connection is weak - Rxy = 0.1 - 0.3
Let us first consider the coefficient of determination for a simple linear regression, also called the coefficient of pair determination.
Based on the considerations outlined in Section 3.1, it is now relatively easy to find a measure of the accuracy of the regression estimate. We have shown that the total variance can be decomposed into two components - the “unexplained” variance and the variance due to regression. The more in comparison with the more the total variance is formed due to the influence of the explanatory variable x and, therefore, the relationship between the two variables y is more intense. Obviously, it is convenient to use the relation

This ratio indicates how much of the total (total) dispersion of the values of y is due to the variability of the variable x. The greater the proportion of the total variance, the better the chosen regression function fits the empirical data. The less the empirical values of the dependent variable deviate from the regression line, the better the regression function is defined. This is where the name of the relation (3.6) comes from - the coefficient of determination. The index at the coefficient indicates the variables, the relationship between which is being studied. In this case, at the beginning, the index contains the designation of the dependent variable, and then the explanatory one.
From the definition of the coefficient of determination as a relative share, it is obvious that it is always in the range from 0 to 1:
![]()
If then all empirical values (all points of the correlation field) lie on the regression line. This means that for In this case, one speaks of a strict linear relationship (linear function) between the variables at them. If the variance due to the regression is zero and
The “unexplained” variance is equal to the total variance. In this case, the regression line is then parallel to the abscissa axis. There can be no question of any numerical linear dependence of the variable y on in its statistical understanding. In this case, the regression coefficient differs insignificantly from zero.
So, the closer you get to one, the better the regression is defined.
The coefficient of determination is a dimensionless quantity and therefore it does not depend on the change in the units of measurement of the variables y and x (in contrast to the regression parameters). The coefficient does not react to the transformation of variables.
Here are some modifications of formula (3.6), which, on the one hand, will contribute to understanding the essence of the coefficient of determination, and on the other hand, will be useful for practical calculations. Substituting the expression for in (3.6) and taking into account (1.8) and (3.1), we obtain:
![]()
This formula once again confirms that the "explained" variance in the numerator (3.6) is proportional to the variance of the variable x, since it is an estimate of the regression parameter.
Substituting expression (2.26) instead of it and taking into account the definitions of variances as well as averages x and y, we obtain a formula for the coefficient of determination that is convenient for calculating:


From (3.9) it follows that always With the help of (3.9) one can relatively easily determine the coefficient of determination. This formula contains only those quantities that are used to calculate the estimates of the regression parameters and therefore are available in the worksheet. Formula (3.9) has the advantage that the calculation of the coefficient of determination by it is carried out directly from empirical data. You do not need to find the parameter estimates and regression values in advance. This circumstance plays an important role for subsequent studies, since before carrying out the regression analysis, we can check to what extent the investigated regression is determined by the explanatory factors included in it.
variables. If the coefficient of determination is too small, then you need to look for other variable factors that cause the dependent variable. It should be noted that the coefficient of determination satisfactorily meets its purpose with sufficient a large number observations. But in any case, it is necessary to check the significance of the coefficient of determination. This issue will be discussed in Section 8.6.
Let us return to the consideration of the "unexplained" variance that arises due to the variability of other factor-variables that do not depend on x, as well as due to chances. The greater its share in the total variance, the less, the more indefinite the relationship between y and x appears, the more the connection between them is obscured. Based on these considerations, we can use “unexplained” variance to characterize the uncertainty or uncertainty in the regression. The following relationship serves as a measure of the uncertainty of the regression:

It is easy to see that
![]()
![]()
Hence, it is obvious that there is no need to separately calculate the measure of uncertainty, and its estimate can be easily obtained from (3.11).
Now let's return to our examples and determine the coefficients of determination for the obtained regression equations.
Let's calculate the coefficient of determination according to the example from section 2.4 (dependence of labor productivity on the level of mechanization of work). We use for this the formula (3.9), and we borrow intermediate results of calculations from table. 3:
Hence, we conclude that in the case of a simple regression, 93.8% of the total variance of labor productivity at the enterprises under consideration is due to a variation in the indicator of work mechanization. Thus, the variability of the variable x almost completely explains the variation of the variable y.
For this example, the uncertainty coefficient, i.e. only 6.2% of the total variance, cannot be explained by the dependence of labor productivity on the level of mechanization of work.
Let us calculate the coefficient of determination according to the example data from Section 2.5 (the dependence of the volume of production on fixed assets). Necessary
intermediate calculation results are given in section 2.5 when determining the estimates of the regression coefficients:
Thus, 91.1% of the total variance in the volume of production of the studied enterprises is due to the variability of the values of fixed assets at these enterprises. This regression is almost completely exhausted by the explanatory variable included in it. The uncertainty factor is 0.089, or 8.9%.
It should be noted that the formulas given in this section are intended to calculate the coefficient of determination based on the results of a large sample in the case of a simple regression. But more often than not, you have to be content with a small sample size. In this case, the corrected coefficient of determination is calculated taking into account the corresponding number of degrees of freedom. The formula for the corrected coefficient of determination for the general case of explanatory variables will be given in the next section. From it it is easy to obtain the formula for the corrected coefficient of determination in the case of a simple regression
Determination coefficient
To assess the quality of fitting a linear function (the proximity of the location of the actual data to the calculated regression line), a square is calculated linear coefficient correlation, called the coefficient of determination.
Verification is carried out on the basis of research determination coefficient and analysis of variance.
The regression model shows that the variation in Y can be explained by the variation in the independent variable X and the value of the disturbance e. We want to know how much the variation in Y is due to the change in X and how much it is due to random causes. In other words, we need to know how well the calculated regression equation matches the actual data, i.e. how small is the variation in the data around the regression line.
To assess the degree of compliance with the regression line, it is necessary to calculate the coefficient of determination, the essence of which can be well understood by considering the decomposition of the total sum of squares of deviations of the variable Y from the mean value into two parts - "explained" and "unexplained" (Fig. 4).
From fig. 4 it is seen that ![]() .
.
Let us square both sides of this equality and sum over all i from 1 to n.
Let's rewrite the sum of the products in the form:

The following properties are used here:
2) method least squares(OLS) proceeds from the condition:
necessary condition the existence of a minimum of the function Q is the equality to zero of its first partial derivatives with respect to b 0 and b 1.
![]() .
.
Or ![]() .
.
Hence it follows that.
 |
 |
 Y i
Y i

 |
|||||
Figure 4. Structure of variation of the dependent variable Y
Thus, as a result, we will have:
 (1)
(1)
The total sum of squares of deviations of individual values of the dependent variable Y from the mean is caused by the influence of many reasons, which we conditionally divided into two groups: factor X and other factors (random influences). If the X factor does not affect the result (Y), then the regression line on the graph is parallel to the abscissa axis and. Then the entire variance of the dependent variable Y is due to the influence of other factors, and the total sum of the squares of the deviations coincides with the residual sum of squares. If other factors do not affect the result, then Y is functionally related to X, and the residual sum of squares is zero. In this case, the sum of squares of the deviations explained by the regression is the same as the total sum of squares.
We divide both sides of equation (1) by the left side (by the total sum of squares), we get:
 (2)
(2)
The proportion of the variance of the dependent variable explained by the regression is called coefficient of determination and is denoted by R 2. From (2) the coefficient of determination is determined:
 . (3)
. (3)
The value of the coefficient of determination is in the range from 0 to 1 and serves as one of the criteria for checking the quality of a linear model. The greater the proportion of the explained variation, the correspondingly less role other factors, therefore, the linear model approximates the initial data well, and it can be used to predict the values of the effective indicator.
the coefficient of determination takes values from zero when NS do not affect Y, up to unity, when the change in Y is fully explained by the change NS... Thus, the coefficient of determination characterizes the "completeness" of the model.
Advantages of the coefficient of determination: it is easy to calculate, intuitive and has a clear interpretation. But despite this, its use is sometimes associated with problems:
· It is impossible to compare the values of R 2 for models with different dependent variables;
· R 2 always increases as new variables are included in the model. This property of R 2 can create an incentive for the researcher to unreasonably include additional variables in the model, and in any case it becomes problematic to determine whether the additional variable improves the quality of the model;
· R 2 is of little use for assessing the quality of time series models, since in such models, its value often reaches 0.9 and higher; differentiating models based on this coefficient is a difficult task.
One of the listed problems - an increase in R 2 when additional variables are introduced into the model - is solved by correcting the coefficient for a decrease in the number of degrees of freedom as a result of the appearance of additional variables in the model.
Adjusted coefficient of determination is calculated like this:
![]() , (4)
, (4)
As you can see from the formula, adding variables will increase only if the growth of R 2 will "outweigh" the increase in the number of variables. Really,
those. the proportion of residual variance with the inclusion of new variables should decrease, but multiplied by it, at the same time, will increase with an increase in the number of variables included in the model (p); as a result, if the positive effect from the inclusion of new factors "outweighs" the change in the number of degrees of freedom, then it will increase; otherwise, it may decrease.
The quality of the equation (the adequacy of the selected model to the empirical data) is assessed using the F-test. The essence of the assessment is to test the null hypothesis H 0 about the statistical insignificance of the regression equation and the coefficient of determination. For this, a comparison is made between the actual F fact and the critical (tabular) F table of the F-Fisher's test values:
![]() . (5)
. (5)
If the hypothesis is valid
H 0: b 0 = b 1 =… = b p = 0 (or R 2 truth = 0)
statistics F fact must obey F - distribution with the number of degrees of freedom of the numerator and denominator, respectively equal
n 1 = p and n 2 = n - p - 1.
The tabular value of the F-test for the probability 0.95 (or 0.99) and the number of degrees of freedom n 1 = p, n 2 = n - p - 1 is compared with the calculated one; when the inequality F> F table is fulfilled, the null hypothesis that the true value of the coefficient of determination is equal to zero is rejected; this gives reason to believe that the model is adequate to the process under study.
For a paired model, in the test criterion for R 2, the numerator corresponds to one degree of freedom and (n - 2) degrees of freedom corresponds to the denominator. The calculation of the F-criterion to test the significance of R 2 is performed as follows:
 .
.
Referring to the F-table, we see that table value at a 5% significance level for n 1 = 1 and n 2 = 50 is approximately 4. Since the calculated value of the F-criterion is greater than the tabular value, then with a confidence level of 0.95 we reject the null hypothesis that the true value of the coefficient of determination is zero.
Thus, we can conclude that the coefficient of determination (and hence the model as a whole) is a statistically reliable indicator of the relationship of the stock indices under consideration.
Square root from the value of the coefficient of determination for the paired model is correlation coefficient- an indicator of the tightness of communication.
The third stage - checking the feasibility of the basic premises of classical regression - is a subject for further study.
Determination coefficient
Determination coefficient ( - R-square) is the proportion of the variance of the dependent variable explained by the considered dependence model, that is, the explanatory variables. More precisely, it is one minus the proportion of unexplained variance (variance of the random error of the model, or conditional variance of the dependent variable in terms of factors) in the variance of the dependent variable. It is considered as a universal measure of the relationship of one random variable from many others. In the particular case of a linear relationship, it is the square of the so-called multiple correlation coefficient between the dependent variable and the explanatory variables. In particular, for a paired linear regression model, the coefficient of determination is equal to the square of the usual coefficient of correlation between y and x.
Definition and formula
The true coefficient of determination of the model of the dependence of a random variable y on factors x is determined as follows:
where is the conditional (by factors x) variance of the dependent variable (variance of the random error of the model).
V this definition true parameters characterizing the distribution are used random variables... If we use a sample estimate of the values of the corresponding variances, then we get a formula for the sample coefficient of determination (which is usually meant by the coefficient of determination):
where is the sum of the squares of the regression residuals, are the actual and calculated values of the explained variable.
Total sum of squares.
In the case of linear regression with constant, where is the explained sum of squares, so we get a simpler definition in this case - the coefficient of determination is the proportion of the explained sum of squares in the total:
It should be emphasized that this formula is valid only for a model with a constant; in general, it is necessary to use the previous formula.
Interpretation
1. The coefficient of determination for the model with a constant takes values from 0 to 1. The closer the value of the coefficient to 1, the stronger the dependence. When evaluating regression models, this is interpreted as fitting the model to the data. For acceptable models, it is assumed that the coefficient of determination should be at least at least 50% (in this case, the multiple correlation coefficient exceeds 70% in modulus). Models with a coefficient of determination above 80% can be considered quite good (the correlation coefficient exceeds 90%). The value of the coefficient of determination 1 means the functional relationship between the variables.
2. In the absence of a statistical relationship between the variable being explained and the factors, the statistics for linear regression has an asymptotic distribution, where is the number of factors in the model (see test of Lagrange multipliers). In the case of linear regression with normally distributed random errors, the statistics have an exact (for samples of any size) Fisher distribution (see F-test). Information on the distribution of these quantities allows one to check statistical significance regression model based on the value of the coefficient of determination. In fact, these tests test the hypothesis that the true coefficient of determination is equal to zero.
Disadvantage and alternative indicators
The main problem of (selective) application is that its value increases ( not decreases) from adding new variables to the model, even if these variables have nothing to do with the variable being explained! Therefore, comparison of models with different amounts factors using the coefficient of determination, generally speaking, is incorrect. Alternative indicators can be used for these purposes.
Adjusted
In order to be able to compare models with a different number of factors so that the number of regressors (factors) does not affect the statistics, it is usually used corrected coefficient of determination, which uses unbiased variance estimates:
which gives a penalty for additionally included factors, where n is the number of observations, and k is the number of parameters.
This indicator is always less than one, but theoretically it can be less than zero (only with a very small value of the usual coefficient of determination and a large number of factors). Therefore, the interpretation of the indicator as a "share" is lost. Nevertheless, the use of the indicator in comparison is quite reasonable.
For models with the same dependent variable and the same sample size, comparing the models using the adjusted coefficient of determination is equivalent to comparing them using the residual variance or standard error of the model. The only difference is that the smaller the better.
Information criteria
AIC- Akaike information criterion - used exclusively for comparing models. The lower the value, the better. Often used to compare time series models with varying amounts of lag.
, where k- the number of model parameters.
BIC or SC- Schwarz's Bayesian Information Criterion - used and interpreted similarly to AIC.
... Gives a greater penalty for including unnecessary lags in the model than AIC.
-general (extended)
In the absence of a constant in linear multiple OLS regression, the properties of the coefficient of determination may be violated for a specific implementation. Therefore, regression models with and without an intercept cannot be compared by criterion. This problem is solved by constructing a generalized coefficient of determination, which coincides with the initial one for the case of OLS regression with a free term, and for which the four properties listed above are satisfied. The essence of this method is to consider the projection of a unit vector onto the plane of explanatory variables.
For regression case without intercept:
,
where X is a matrix of nxk values of factors, is a projector onto the X plane, where is a unit vector nx1.
with the condition of slight modification, is also suitable for comparing regressions constructed with the help of: OLS, generalized least squares (GLS), conditional least squares (ULSs), generalized-conditional least squares (GLSs).
Comment
High values of the coefficient of determination, generally speaking, do not indicate the presence of a causal relationship between the variables (as well as in the case of the usual coefficient of correlation). For example, if the explained variable and factors that are not actually associated with the explained change have increasing dynamics, then the coefficient of determination will be quite high. Therefore, the logical and semantic adequacy of the model is of paramount importance. In addition, it is necessary to use criteria for a comprehensive analysis of the quality of the model.
see also
Notes (edit)
Links
- Applied Econometrics (journal)
Wikimedia Foundation. 2010.
- De Ritis coefficient
- Natural light factor
See what the "Coefficient of determination" is in other dictionaries:
DETERMINATION COEFFICIENT- assessment of the quality (explanatory ability) of the regression equation, the proportion of variance of the explained dependent variable y: R2 = 1 Sum (yi yzi) 2 / Sum (yi y) 2, where yi is the observed value of the dependent variable y, yzi is the value of the dependent variable, ... ... Sociology: Encyclopedia
Determination coefficient- squared coefficient linear correlation Pearson, is interpreted as the proportion of variance in the dependent variable explained by the independent variable ... Sociological Dictionary Socium
Determination coefficient- A measure of how well the dependent and independent variables are related in regression analysis. For example, the percentage of the change in the return on an asset explained by the return on the market portfolio ... Investment Dictionary
Determination coefficient- (COEFFICIENT OF DETERMINATION) is determined when constructing a linear regression relationship. Equal to the proportion of variance in the dependent variable associated with variation in the independent variable ... Financial glossary
Correlation coefficient- (Correlation coefficient) The correlation coefficient is a statistical indicator of the dependence of two random variables. Determination of the correlation coefficient, types of correlation coefficients, properties of the correlation coefficient, calculation and application ... ... Investor encyclopedia
In clauses 3.3, 4.1, the formulation of the problem of estimating the linear regression equation is considered, and a method for its solution is shown. However, the estimation of the parameters of a specific equation is only a separate stage in the long and complex process of building an econometric model. The first equation evaluated is very rarely satisfactory in all respects. Usually it is necessary to gradually select the connection formula and the composition of the explanatory variables, analyzing at each stage the quality of the estimated dependence. This quality analysis includes a statistical and substantive component. Checking the statistical quality of the estimated equation consists of the following elements:
checking the statistical significance of each coefficient of the regression equation;
checking the overall quality of the regression equation;
checking data properties that are supposed to be executed
when evaluating an equation.
The meaningful component of the quality analysis is understood as considering the economic meaning of the estimated regression equation: were the explanatory factors important from the theoretical point of view really significant; positive or negative coefficients showing the direction of influence of these factors; whether the estimates of the regression coefficients fell into the intervals assumed from theoretical considerations.
The methodology for checking the statistical significance of each individual coefficient of the linear regression equation was discussed in the previous chapter. Now let's move on to other stages of checking the quality of the equation.
4.2.1. Checking the overall quality of the regression equation. Determination coefficient r2
To analyze the overall quality of the estimated linear regression, the coefficient of determination is usually used R 2 ... For the case of paired regression, this is the square of the correlation coefficient of the variables NS and y... The coefficient of determination is calculated by the formula
Determination coefficient characterizes the fraction of variation (spread) of the dependent variable, explained using a given equation. The variance of the dependent variable is usually used as a measure of the spread of the dependent variable, and the residual variation can be measured as the variance of the deviations around the regression line. If the numerator and denominator of the fraction subtracted from the unit are divided by the number of observations NS, then we obtain, respectively, sample estimates of the residual variance and variance of the dependent variable at. The ratio of the residual and total variances represents a fraction of the unexplained variance. If this proportion is subtracted from unity, then we get the proportion of the variance of the dependent variable, explained using regression. Sometimes, when calculating the coefficient of determination, to obtain unbiased estimates of the variance in the numerator and denominator of the fraction subtracted from the unit, a correction is made for the number of degrees of freedom; then
 .
.
or, for paired regression, where the number of independent variables T equals 1,

The numerator of the fraction that is subtracted from one is the sum of the squares of the deviations of the observations at i from the regression line, in the denominator - from the mean value of the variable at. Thus, this fraction is small (and the coefficientR 2
is obviously close to unity) if the scatter of points around the regression line is much less than around the mean... OLS allows you to find a straight line for which the sum e i 2
is minimal, and  represents one of the possible lines for which the condition .
Therefore, the value in the numerator of the fraction subtracted from the unit is less than the value in its denominator, otherwise the regression line chosen by the OLS would be a straight line
represents one of the possible lines for which the condition .
Therefore, the value in the numerator of the fraction subtracted from the unit is less than the value in its denominator, otherwise the regression line chosen by the OLS would be a straight line  .
Thus, the coefficient of determination R
2
is a measure that allows you to determine to what extent the found regression line gives the best result for explaining the behavior of the dependent variable y, than just a horizontal line
.
Thus, the coefficient of determination R
2
is a measure that allows you to determine to what extent the found regression line gives the best result for explaining the behavior of the dependent variable y, than just a horizontal line  .
.
The meaning of the coefficient of determination can be explained in a slightly different way. It can be shown that  , where k i =
, where k i = - deviation i‑
th point on the regression line from
- deviation i‑
th point on the regression line from 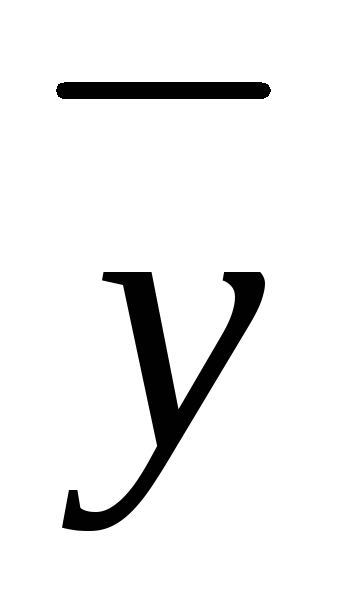 .
In this formula, the value on the left side can be interpreted as a measure of the total spread (variation) of the variable y, the first term on the right-hand side
.
In this formula, the value on the left side can be interpreted as a measure of the total spread (variation) of the variable y, the first term on the right-hand side  - as a measure of the dispersion explained by the regression and the second term
- as a measure of the dispersion explained by the regression and the second term  -
as a measure of residual, unexplained scatter (scatter of points around the regression line). If we divide this formula by its left side and regroup the terms, then
-
as a measure of residual, unexplained scatter (scatter of points around the regression line). If we divide this formula by its left side and regroup the terms, then
 , that is, the coefficient of determination R
2 is the proportion of the explained part of the variation of the dependent variable (or the proportion of the explained variance, if the numerator and denominator are divided by n
or NS- 1).
Often the coefficient of determination R
2
are illustrated in Fig. 4.2
, that is, the coefficient of determination R
2 is the proportion of the explained part of the variation of the dependent variable (or the proportion of the explained variance, if the numerator and denominator are divided by n
or NS- 1).
Often the coefficient of determination R
2
are illustrated in Fig. 4.2

Rice. 4.2.
Here TSS(Total Sum of Squares) - total variance of a variable y, ESS (Explained Sum of Squares) - the scatter explained by the regression, USS (Unexplained Sum of Squares) - scatter unexplained by regression. It can be seen from the figure that with an increase in the explained share of the spread, the coefficient R 2 - approaching one. In addition, it can be seen from the figure that with the addition of one more variable R 2 usually increases, however if the explanatory variables NS 1 and NS 2 strongly correlate with each other, then they explain the same part of the spread of the variable y, and in this case it is difficult to identify the contribution of each of the variables to explain the behavior at.
If there is a statistically significant linear relationship between the values NS and at, then the coefficient R 2 is close to unity. However, it can be close to unity simply due to the fact that both of these quantities have a pronounced time trend, which is not associated with their causal interdependence. In an economy, usually volume indicators (income, consumption, investment) have such a trend, but tempo and relative indicators (productivity, growth rates, shares, ratios) do not always. Therefore, when evaluating linear regressions over time series of volumetric indicators (for example, the dependence of output on resource inputs or consumption on income), the value R 2 is usually very close to one. This suggests that the dependent variable cannot be described simply as equal to its mean value, but this is obvious in advance, since it has a time trend.
If there are not time series, but a cross-sectional sample, that is, data on objects of the same type at the same moment in time, then for the linear regression equation estimated from them, the value R 2 does not usually exceed the level of 0.6-0.7. The same is usually the case for time series regressions if they are not trendy. In macroeconomics, examples of such dependencies are the relationship between relative, specific, and rate indicators: the dependence of the inflation rate on the unemployment rate, the rate of accumulation on the interest rate, and the rate of output growth on the rate of increase in resource costs. Thus, when building macroeconomic models, especially based on time series of data, it is necessary to take into account whether the variables included in them are volumetric or relative, whether they have a time trend of 1.
The exact limit of acceptability of the indicator R
2 is impossible to indicate at once for all cases. It is necessary to take into account both the number of degrees of freedom of the equation, and the presence of trends in the variables, and the meaningful interpretation of the equation. Index R
2
it may even turn out to be negative. As a rule, this happens in an equation without a free term y =  ... Evaluation of such an equation is carried out, as in the general case, using the least squares method. However, the set of choices is significantly narrowed in this case: not all possible straight lines or hyperplanes are considered, but only those passing through the origin. The magnitude R
2
turns out negative if the spread of the values of the dependent variable around a straight line (hyperplane)
... Evaluation of such an equation is carried out, as in the general case, using the least squares method. However, the set of choices is significantly narrowed in this case: not all possible straight lines or hyperplanes are considered, but only those passing through the origin. The magnitude R
2
turns out negative if the spread of the values of the dependent variable around a straight line (hyperplane)  less than around even the best straight line (hyperplane) of coordinates passing through the origin. Negative value R
2
in the equation
less than around even the best straight line (hyperplane) of coordinates passing through the origin. Negative value R
2
in the equation
 speaks of the advisability of introducing a free member into it. This situation is illustrated in Fig. 4.3.
speaks of the advisability of introducing a free member into it. This situation is illustrated in Fig. 4.3.
Line 1 on it is a graph of the regression equation without an intercept (it passes through the origin), line 2 - with an intercept (it is equal to a 0
), line 3 -  .
Horizontal line 3 gives much less squared deviations e i than line 1, and therefore for the latter the coefficient of determination R
2 will be negative.
.
Horizontal line 3 gives much less squared deviations e i than line 1, and therefore for the latter the coefficient of determination R
2 will be negative.

Rice. 4.3. Lines of linear regression equations y = f (x) without an intercept(1)and with a free member(2)
Correction for the number of degrees of freedom always decreases the value R 2 because (NS- 1)> (p-t- 1). As a result, the value R 2 can also become negative. But this means that it was close to zero before such a correction, and the proportion of variance of the dependent variable explained using the regression equation is very small.

