What gives the confidence interval. Confidence intervals for frequencies and proportions
From this article you will learn:
What confidence interval ?
What is the point 3 sigma rules?
How can this knowledge be put into practice?
Nowadays, due to an overabundance of information associated with a large assortment of products, sales directions, employees, activities, etc., it's hard to pick out the main, which, first of all, is worth paying attention to and making efforts to manage. Definition confidence interval and analysis of going beyond its boundaries of actual values - a technique that help you identify situations, influencing trends. You will be able to develop positive factors and reduce the influence of negative ones. This technology is used in many well-known world companies.
There are so-called alerts", which inform managers stating that the next value in a certain direction went beyond confidence interval. What does this mean? This is a signal that some non-standard event has occurred, which may change the existing trend in this direction. This is the signal to that to sort it out in the situation and understand what influenced it.
For example, consider several situations. We have calculated the sales forecast with forecast boundaries for 100 commodity items for 2011 by months and actual sales in March:
- By " sunflower oil» broke through the upper limit of the forecast and did not fall into the confidence interval.
- For "Dry yeast" went beyond the lower limit of the forecast.
- On "Oatmeal Porridge" broke through the upper limit.
For the rest of the goods, the actual sales were within the specified forecast boundaries. Those. their sales were in line with expectations. So, we identified 3 products that went beyond the borders, and began to figure out what influenced the going beyond the borders:
- With Sunflower Oil, we entered a new trading network, which gave us additional sales volume, which led to going beyond the upper limit. For this product, it is worth recalculating the forecast until the end of the year, taking into account the forecast for sales to this chain.
- For Dry Yeast, the car got stuck at customs, and there was a shortage within 5 days, which affected the decline in sales and going beyond the lower border. It may be worthwhile to figure out what caused the cause and try not to repeat this situation.
- For Oatmeal, a sales promotion was launched, which resulted in a significant increase in sales and led to an overshoot of the forecast.
We identified 3 factors that influenced the overshoot of the forecast. There can be many more of them in life. To improve the accuracy of forecasting and planning, the factors that lead to the fact that actual sales can go beyond the forecast, it is worth highlighting and building forecasts and plans for them separately. And then take into account their impact on the main sales forecast. You can also regularly evaluate the impact of these factors and change the situation for the better for by reducing the influence of negative and increasing the influence of positive factors.
With a confidence interval, we can:
- Highlight destinations, which are worth paying attention to, because events have occurred in these areas that may affect change in trend.
- Determine Factors that actually make a difference.
- To accept weighted decision(for example, about procurement, when planning, etc.).
Now let's look at what a confidence interval is and how to calculate it in Excel using an example.
What is a confidence interval?
The confidence interval is the forecast boundaries (upper and lower), within which with given probability(sigma) get the actual values.
Those. we calculate the forecast - this is our main benchmark, but we understand that the actual values are unlikely to be 100% equal to our forecast. And the question arises to what extent may get actual values, if the current trend continues? And this question will help us answer confidence interval calculation, i.e. - upper and lower bounds of the forecast.
What is a given probability sigma?
When calculating confidence interval we can set probability hits actual values within the given forecast limits. How to do it? To do this, we set the value of sigma and, if sigma is equal to:
3 sigma- then, the probability of hitting the next actual value in the confidence interval will be 99.7%, or 300 to 1, or there is a 0.3% probability of going beyond the boundaries.
2 sigma- then, the probability of hitting the next value within the boundaries is ≈ 95.5%, i.e. the odds are about 20 to 1, or there is a 4.5% chance of going out of bounds.
1 sigma- then, the probability is ≈ 68.3%, i.e. the chances are about 2 to 1, or there is a 31.7% chance that the next value will fall outside the confidence interval.
We formulated 3 Sigma Rule,which says that hit probability another random value into the confidence interval with a given value three sigma is 99.7%.
The great Russian mathematician Chebyshev proved a theorem that there is a 10% chance of going beyond the boundaries of a forecast with a given value of three sigma. Those. the probability of falling into the 3 sigma confidence interval will be at least 90%, while an attempt to calculate the forecast and its boundaries “by eye” is fraught with much more significant errors.
How to independently calculate the confidence interval in Excel?
Let's consider the calculation of the confidence interval in Excel (ie the upper and lower bounds of the forecast) using an example. We have a time series - sales by months for 5 years. See attached file.
To calculate the boundaries of the forecast, we calculate:
- Sales forecast().
- Sigma - standard deviation forecast models from actual values.
- Three sigma.
- Confidence interval.
1. Sales forecast.
=(RC[-14] (data in time series)-RC[-1] (model value))^2(squared)

3. Sum for each month the deviation values from stage 8 Sum((Xi-Ximod)^2), i.e. Let's sum January, February... for each year.
To do this, use the formula =SUMIF()
SUMIF(array with numbers of periods inside the cycle (for months from 1 to 12); reference to the number of the period in the cycle; reference to an array with squares of the difference between the initial data and the values of the periods)

4. Calculate the standard deviation for each period in the cycle from 1 to 12 (stage 10 in the attached file).
To do this, from the value calculated at stage 9, we extract the root and divide by the number of periods in this cycle minus 1 = ROOT((Sum(Xi-Ximod)^2/(n-1))
Let's use formulas in Excel =ROOT(R8 (reference to (Sum(Xi-Ximod)^2)/(COUNTIF($O$8:$O$67 (reference to an array with cycle numbers); O8 (reference to a specific cycle number, which we consider in the array))-1))
Using the Excel formula = COUNTIF we count the number n

By calculating the standard deviation of the actual data from the forecast model, we obtained the sigma value for each month - stage 10 in the attached file .
3. Calculate 3 sigma.
At stage 11, we set the number of sigmas - in our example, "3" (stage 11 in the attached file):

Also practical sigma values:
1.64 sigma - 10% chance of going over the limit (1 chance in 10);
1.96 sigma - 5% chance of going out of bounds (1 chance in 20);
2.6 sigma - 1% chance of going out of bounds (1 in 100 chance).
5) We calculate three sigma, for this we multiply the “sigma” values \u200b\u200bfor each month by “3”.

3. Determine the confidence interval.
- Upper forecast limit- sales forecast taking into account growth and seasonality + (plus) 3 sigma;
- Lower Forecast Bound- sales forecast taking into account growth and seasonality - (minus) 3 sigma;
For the convenience of calculating the confidence interval for a long period (see attached file), we use the Excel formula =Y8+VLOOKUP(W8;$U$8:$V$19;2;0), where
Y8- sales forecast;
W8- the number of the month for which we will take the value of 3 sigma;
Those. Upper forecast limit= "sales forecast" + "3 sigma" (in the example, VLOOKUP(month number; table with 3 sigma values; column from which we extract the sigma value equal to the month number in the corresponding row; 0)).

Lower Forecast Bound= "sales forecast" minus "3 sigma".
So, we have calculated the confidence interval in Excel.
Now we have a forecast and a range with boundaries within which the actual values will fall with a given probability sigma.
In this article, we looked at what sigma is and rule of three sigma, how to determine the confidence interval and what you can use this technique for in practice.
Accurate forecasts and success to you!
How Forecast4AC PRO can help youwhen calculating the confidence interval?:
Forecast4AC PRO will automatically calculate the upper or lower forecast limits for more than 1000 time series at the same time;
The ability to analyze the boundaries of the forecast in comparison with the forecast, trend and actual sales on the chart with one keystroke;
In the Forcast4AC PRO program, it is possible to set the sigma value from 1 to 3.
Join us!
Download Free Forecasting and Business Intelligence Apps:

- Novo Forecast Lite- automatic forecast calculation in excel.
- 4analytics- ABC-XYZ analysis and analysis of emissions in Excel.
- Qlik Sense Desktop and Qlik ViewPersonal Edition - BI systems for data analysis and visualization.
Test the features of paid solutions:
- Novo Forecast PRO- forecasting in Excel for large data arrays.
The mind is not only in knowledge, but also in the ability to apply knowledge in practice. (Aristotle)
Confidence intervals
general review
Taking a sample from the population, we will obtain a point estimate of the parameter of interest to us and calculate the standard error in order to indicate the accuracy of the estimate.
However, for most cases, the standard error as such is not acceptable. It is much more useful to combine this measure of precision with an interval estimate for the population parameter.
This can be done by using knowledge of the theoretical probability distribution of the sample statistic (parameter) in order to calculate a confidence interval (CI - Confidence Interval, CI - Confidence Interval) for the parameter.
In general, the confidence interval extends the estimates in both directions by some multiple of the standard error ( given parameter); the two values (confidence limits) that define the interval are usually separated by a comma and enclosed in parentheses.
Confidence interval for mean
Using the normal distribution
The sample mean has a normal distribution if the sample size is large, so knowledge about normal distribution when considering the sample mean.
In particular, 95% of the distribution of the sample means is within 1.96 standard deviations (SD) of the population mean.
When we have only one sample, we call this the standard error of the mean (SEM) and calculate the 95% confidence interval for the mean as follows:
If this experiment is repeated several times, then the interval will contain the true population mean 95% of the time.
This is usually a confidence interval, such as the range of values within which the true population mean (general mean) lies with a 95% confidence level.
Although it is not quite strict (the population mean is a fixed value and therefore cannot have a probability related to it) to interpret the confidence interval in this way, it is conceptually easier to understand.
Usage t- distribution
You can use the normal distribution if you know the value of the variance in the population. Also, when the sample size is small, the sample mean follows a normal distribution if the data underlying the population are normally distributed.
If the data underlying the population are not normally distributed and/or the general variance (population variance) is unknown, the sample mean obeys Student's t-distribution.
Calculate the 95% confidence interval for the population mean as follows:
Where - percentage point (percentile) t- Student distribution with (n-1) degrees of freedom, which gives a two-tailed probability of 0.05.
In general, it provides a wider interval than when using a normal distribution, because it takes into account the additional uncertainty that is introduced by estimating the population standard deviation and/or due to the small sample size.
When the sample size is large (of the order of 100 or more), the difference between the two distributions ( t-student and normal) is negligible. However, always use t- distribution when calculating confidence intervals, even if the sample size is large.
Usually 95% CI is indicated. Other confidence intervals can be calculated, such as 99% CI for the mean.
Instead of product of standard error and table value t- distribution that corresponds to a two-tailed probability of 0.05 multiply it (standard error) by a value that corresponds to a two-tailed probability of 0.01. This is a wider confidence interval than the 95% case because it reflects increased confidence that the interval does indeed include the population mean.
Confidence interval for proportion
The sampling distribution of proportions has a binomial distribution. However, if the sample size n reasonably large, then the proportion sample distribution is approximately normal with mean .
Estimate by sampling ratio p=r/n(where r- the number of individuals in the sample with the characteristics of interest to us), and the standard error is estimated:
The 95% confidence interval for the proportion is estimated:

If the sample size is small (usually when np or n(1-p) smaller 5
), then the binomial distribution must be used in order to calculate the exact confidence intervals.
Note that if p expressed as a percentage, then (1-p) replaced by (100p).
Interpretation of confidence intervals
When interpreting the confidence interval, we are interested in the following questions:
How wide is the confidence interval?
A wide confidence interval indicates that the estimate is imprecise; narrow indicates a fine estimate.
The width of the confidence interval depends on the size of the standard error, which in turn depends on the sample size, and when considering a numeric variable from the variability of the data, give wider confidence intervals than studies of a large data set of few variables.
Does the CI include any values of particular interest?
You can check whether the likely value for a population parameter falls within a confidence interval. If yes, then the results are consistent with this likely value. If not, then it is unlikely (for a 95% confidence interval, the chance is almost 5%) that the parameter has this value.
Confidence intervals ( English Confidence Intervals) one of the types of interval estimates used in statistics, which are calculated for a given level of significance. They allow the assertion that the true value of an unknown statistical parameter population is in the obtained range of values with a probability that is given by the selected level statistical significance.
Normal distribution
When the variance (σ 2 ) of the population of data is known, a z-score can be used to calculate confidence limits (boundary points of the confidence interval). Compared to using a t-distribution, using a z-score will not only provide a narrower confidence interval, but also provide more reliable estimates of the mean and standard deviation (σ), since the Z-score is based on a normal distribution.
Formula
To determine the boundary points of the confidence interval, provided that the standard deviation of the population of data is known, the following formula is used
| L = X - Z α/2 | σ |
| √n |
Example
Assume that the sample size is 25 observations, expected value the sample is 15, and the population standard deviation is 8. For significance level α=5%, the Z-score is Z α/2 =1.96. In this case, the lower and upper limits of the confidence interval will be
| L = 15 - 1.96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1.96 | 8 | = 18,136 |
| √25 |
Thus, we can state that with a probability of 95% the mathematical expectation of the general population will fall in the range from 11.864 to 18.136.
Methods for narrowing the confidence interval
Let's say the range is too wide for the purposes of our study. There are two ways to decrease the confidence interval range.
- Reduce the level of statistical significance α.
- Increase the sample size.
Reducing the level of statistical significance to α=10%, we get a Z-score equal to Z α/2 =1.64. In this case, the lower and upper limits of the interval will be
| L = 15 - 1.64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1.64 | 8 | = 17,624 |
| √25 |
And the confidence interval itself can be written as
In this case, we can make the assumption that with a probability of 90%, the mathematical expectation of the general population will fall into the range.
If we want to keep the level of statistical significance α, then the only alternative is to increase the sample size. Increasing it to 144 observations, we obtain the following values of the confidence limits
| L = 15 - 1.96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1.96 | 8 | = 16,307 |
| √144 |
The confidence interval itself will look like this:
Thus, narrowing the confidence interval without reducing the level of statistical significance is only possible by increasing the sample size. If it is not possible to increase the sample size, then the narrowing of the confidence interval can be achieved solely by reducing the level of statistical significance.
Building a confidence interval for a non-normal distribution
If the standard deviation of the population is not known or the distribution is non-normal, the t-distribution is used to construct a confidence interval. This technique is more conservative, which is expressed in wider confidence intervals, compared to the technique based on the Z-score.
Formula
The following formulas are used to calculate the lower and upper limits of the confidence interval based on the t-distribution
| L = X - tα | σ |
| √n |
Student's distribution or t-distribution depends on only one parameter - the number of degrees of freedom, which is equal to the number of individual feature values (the number of observations in the sample). The value of Student's t-test for a given number of degrees of freedom (n) and the level of statistical significance α can be found in the lookup tables.
Example
Assume that the sample size is 25 individual values, the mean of the sample is 50, and the standard deviation of the sample is 28. You need to construct a confidence interval for the level of statistical significance α=5%.
In our case, the number of degrees of freedom is 24 (25-1), therefore, the corresponding tabular value of Student's t-test for the level of statistical significance α=5% is 2.064. Therefore, the lower and upper bounds of the confidence interval will be
| L = 50 - 2.064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2.064 | 28 | = 61,558 |
| √25 |
And the interval itself can be written as
Thus, we can state that with a probability of 95% the mathematical expectation of the general population will be in the range.
Using a t-distribution allows you to narrow the confidence interval, either by reducing statistical significance or by increasing the sample size.
Reducing the statistical significance from 95% to 90% in the conditions of our example, we get the corresponding tabular value of Student's t-test 1.711.
| L = 50 - 1.711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1.711 | 28 | = 59,582 |
| √25 |
In this case, we can say that with a probability of 90% the mathematical expectation of the general population will be in the range.
If we do not want to reduce the statistical significance, then the only alternative is to increase the sample size. Let's say that it is 64 individual observations, and not 25 as in the initial condition of the example. Table value Student's t-test for 63 degrees of freedom (64-1) and the level of statistical significance α=5% is 1.998.
| L = 50 - 1.998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1.998 | 28 | = 56,993 |
| √64 |
This gives us the opportunity to assert that with a probability of 95% the mathematical expectation of the general population will be in the range.
Large Samples
Large samples are samples from a population of data with more than 100 individual observations. Statistical studies have shown that larger samples tend to be normally distributed, even if the distribution of the population is not normal. In addition, for such samples, the use of z-score and t-distribution give approximately the same results when constructing confidence intervals. Thus, for large samples, it is acceptable to use a z-score for a normal distribution instead of a t-distribution.
Summing up
Target– to teach students algorithms for calculating confidence intervals of statistical parameters.
During statistical processing of data, the calculated arithmetic mean, coefficient of variation, correlation coefficient, difference criteria and other point statistics should receive quantitative confidence limits, which indicate possible fluctuations of the indicator up and down within the confidence interval.
Example 3.1
.
The distribution of calcium in the blood serum of monkeys, as previously established, is characterized by the following selective indicators: = 11.94 mg%;  = 0.127 mg%; n= 100. It is required to determine the confidence interval for the general average (
= 0.127 mg%; n= 100. It is required to determine the confidence interval for the general average (  ) with confidence probability P
= 0,95.
) with confidence probability P
= 0,95.
The general average is with a certain probability in the interval:
 , where
, where  – sample arithmetic mean; t- Student's criterion;
– sample arithmetic mean; t- Student's criterion;  is the error of the arithmetic mean.
is the error of the arithmetic mean.
According to the table "Values of Student's criterion" we find the value
 with a confidence level of 0.95 and the number of degrees of freedom k\u003d 100-1 \u003d 99. It is equal to 1.982. Together with the values of the arithmetic mean and statistical error, we substitute it into the formula:
with a confidence level of 0.95 and the number of degrees of freedom k\u003d 100-1 \u003d 99. It is equal to 1.982. Together with the values of the arithmetic mean and statistical error, we substitute it into the formula:
or 11.69  12,19
12,19
Thus, with a probability of 95%, it can be argued that the general average of this normal distribution is between 11.69 and 12.19 mg%.
Example 3.2
. Determine the boundaries of the 95% confidence interval for the general variance (  ) distribution of calcium in the blood of monkeys, if it is known that
) distribution of calcium in the blood of monkeys, if it is known that  = 1.60, with n
= 100.
= 1.60, with n
= 100.
To solve the problem, you can use the following formula:
Where  is the statistical error of the variance.
is the statistical error of the variance.
Find the sample variance error using the formula:  . It is equal to 0.11. Meaning t- criterion with a confidence probability of 0.95 and the number of degrees of freedom k= 100–1 = 99 is known from the previous example.
. It is equal to 0.11. Meaning t- criterion with a confidence probability of 0.95 and the number of degrees of freedom k= 100–1 = 99 is known from the previous example.
Let's use the formula and get:
or 1.38  1,82
1,82
A more accurate confidence interval for the general variance can be constructed using  (chi-square) - Pearson's test. Critical points for this criterion are given in a special table. When using the criterion
(chi-square) - Pearson's test. Critical points for this criterion are given in a special table. When using the criterion  a two-sided significance level is used to construct a confidence interval. For the lower bound, the significance level is calculated by the formula
a two-sided significance level is used to construct a confidence interval. For the lower bound, the significance level is calculated by the formula  , for the upper
, for the upper  . For example, for a confidence level
. For example, for a confidence level  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. Accordingly, according to the table of distribution of critical values
= 0.990. Accordingly, according to the table of distribution of critical values  , with the calculated confidence levels and the number of degrees of freedom k= 100 – 1= 99, find the values
, with the calculated confidence levels and the number of degrees of freedom k= 100 – 1= 99, find the values  and
and  . We get
. We get  equals 135.80, and
equals 135.80, and 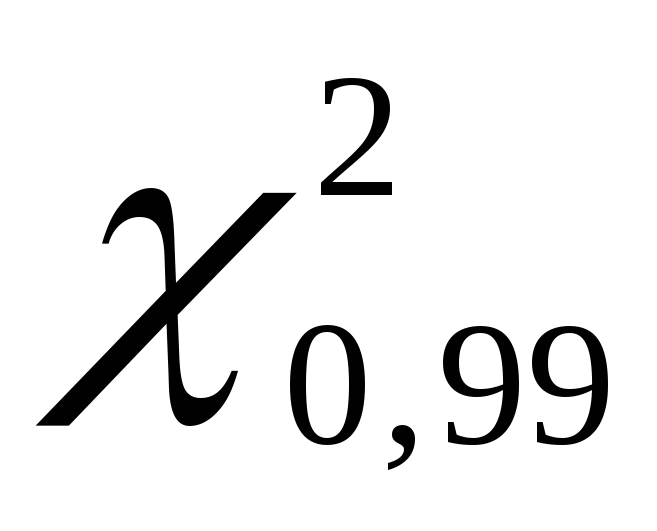 equals 70.06.
equals 70.06.
To find the confidence limits of the general variance using  we use the formulas: for the lower bound
we use the formulas: for the lower bound 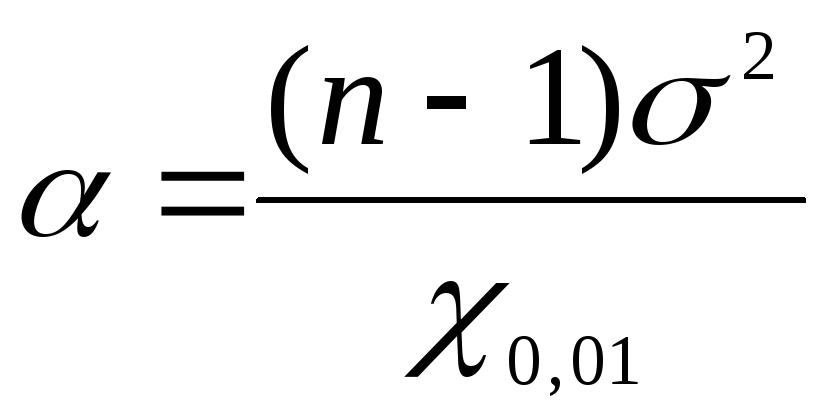 , for the upper bound
, for the upper bound  . Substitute the task data for the found values
. Substitute the task data for the found values  into formulas:
into formulas: 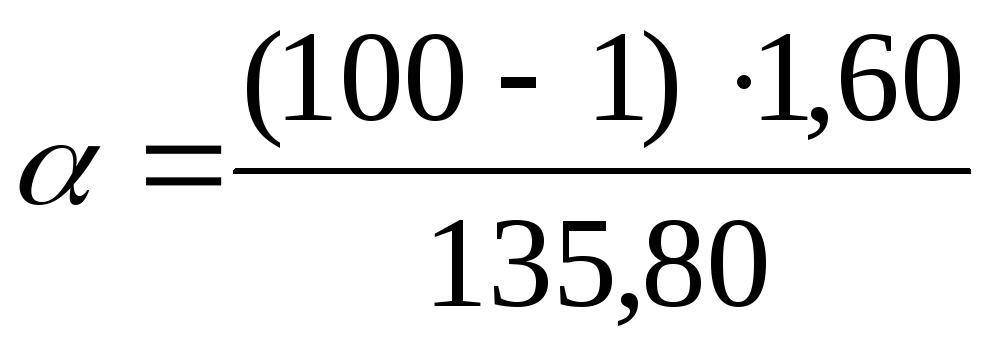 =
1,17;
=
1,17; = 2.26. Thus, with a confidence level P= 0.99 or 99% the general variance will lie in the range from 1.17 to 2.26 mg% inclusive.
= 2.26. Thus, with a confidence level P= 0.99 or 99% the general variance will lie in the range from 1.17 to 2.26 mg% inclusive.
Example 3.3 . Among the 1000 wheat seeds from the lot that arrived at the elevator, 120 seeds infected with ergot were found. It is necessary to determine the probable boundaries of the total proportion of infected seeds in a given batch of wheat.
Confidence limits for the general share for all its possible values should be determined by the formula:
 ,
,
Where n is the number of observations; m is the absolute number of one of the groups; t is the normalized deviation.
The sample fraction of infected seeds is equal to  or 12%. With a confidence level R= 95% normalized deviation ( t-Student's criterion for k
=
or 12%. With a confidence level R= 95% normalized deviation ( t-Student's criterion for k
=
 )t
= 1,960.
)t
= 1,960.
We substitute the available data into the formula:
Hence, the boundaries of the confidence interval are  = 0.122–0.041 = 0.081, or 8.1%;
= 0.122–0.041 = 0.081, or 8.1%;  = 0.122 + 0.041 = 0.163, or 16.3%.
= 0.122 + 0.041 = 0.163, or 16.3%.
Thus, with a confidence level of 95%, it can be stated that the total proportion of infected seeds is between 8.1 and 16.3%.
Example 3.4 . The coefficient of variation, which characterizes the variation of calcium (mg%) in the blood serum of monkeys, was equal to 10.6%. Sample size n= 100. It is necessary to determine the boundaries of the 95% confidence interval for the general parameter CV.
Confidence limits for the general coefficient of variation CV are determined by the following formulas:
 and
and  , where K
intermediate value calculated by the formula
, where K
intermediate value calculated by the formula  .
.
Knowing that with a confidence level R= 95% normalized deviation (Student's t-test for k
=
 )t
= 1.960, pre-calculate the value TO:
)t
= 1.960, pre-calculate the value TO:
 .
.
 or 9.3%
or 9.3%
 or 12.3%
or 12.3%
Thus, the general coefficient of variation with a confidence probability of 95% lies in the range from 9.3 to 12.3%. With repeated samples, the coefficient of variation will not exceed 12.3% and will not fall below 9.3% in 95 cases out of 100.
Questions for self-control:

Tasks for independent solution.
1. The average percentage of fat in milk for lactation of cows of Kholmogory crosses was as follows: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. Set confidence intervals for the overall mean at a 95% confidence level (20 points).
2. On 400 plants of hybrid rye, the first flowers appeared on average 70.5 days after sowing. The standard deviation was 6.9 days. Determine the error of the mean and confidence intervals for the population mean and variance at a significance level W= 0.05 and W= 0.01 (25 points).
3. When studying the length of the leaves of 502 specimens of garden strawberries, the following data were obtained:
 = 7.86 cm; σ = 1.32 cm,
= 7.86 cm; σ = 1.32 cm,  \u003d ± 0.06 cm. Determine the confidence intervals for the arithmetic mean of the population with significance levels of 0.01; 0.02; 0.05. (25 points).
\u003d ± 0.06 cm. Determine the confidence intervals for the arithmetic mean of the population with significance levels of 0.01; 0.02; 0.05. (25 points).
4. When examining 150 adult men, the average height was 167 cm, and σ \u003d 6 cm. What are the limits of the general average and general variance with a confidence probability of 0.99 and 0.95? (25 points).
5. The distribution of calcium in the blood serum of monkeys is characterized by the following selective indicators:
 = 11.94 mg%, σ
= 1,27, n
= 100. Plot a 95% confidence interval for the population mean of this distribution. Calculate the coefficient of variation (25 points).
= 11.94 mg%, σ
= 1,27, n
= 100. Plot a 95% confidence interval for the population mean of this distribution. Calculate the coefficient of variation (25 points).
6. The total nitrogen content in the blood plasma of albino rats at the age of 37 and 180 days was studied. Results are expressed in grams per 100 cm 3 of plasma. At the age of 37 days, 9 rats had: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. At the age of 180 days, 8 rats had: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. Set confidence intervals for the difference with a confidence level of 0.95 (50 points).
7. Determine the boundaries of the 95% confidence interval for the general variance of the distribution of calcium (mg%) in the blood serum of monkeys, if for this distribution the sample size is n = 100, the statistical error of the sample variance s σ 2 = 1.60 (40 points).
8. Determine the boundaries of the 95% confidence interval for the general variance of the distribution of 40 spikelets of wheat along the length (σ 2 = 40.87 mm 2). (25 points).
9. Smoking is considered the main factor predisposing to obstructive pulmonary disease. Passive smoking is not considered such a factor. Scientists questioned the safety of passive smoking and examined the airway in non-smokers, passive and active smokers. To characterize the state of the respiratory tract, we took one of the indicators of the function of external respiration - the maximum volumetric velocity of the middle of exhalation. A decrease in this indicator is a sign of impaired airway patency. Survey data are shown in the table.
|
Number of examined |
Maximum mid-expiratory flow rate, l/s |
||
|
Standard deviation |
|||
|
Non-smokers |
|||
|
work in a non-smoking area | |||
|
work in a smoke-filled room | |||
|
smokers |
|||
|
smokers do not big number cigarettes | |||
|
average number of cigarette smokers | |||
|
smoking a large number of cigarettes | |||
From the table, find the 95% confidence intervals for the general mean and general variance for each of the groups. What are the differences between the groups? Present the results graphically (25 points).
10. Determine the boundaries of the 95% and 99% confidence intervals for the general variance of the number of piglets in 64 farrowings, if the statistical error of the sample variance s σ 2 = 8.25 (30 points).
11. It is known that the average weight of rabbits is 2.1 kg. Determine the boundaries of the 95% and 99% confidence intervals for the general mean and variance when n= 30, σ = 0.56 kg (25 points).
12. In 100 ears, the grain content of the ear was measured ( X), spike length ( Y) and the mass of grain in the ear ( Z). Find confidence intervals for the general mean and variance for P 1
= 0,95, P 2
= 0,99, P 3
= 0.999 if
 = 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2.111, σ z 2 = 0.064. (25 points).
= 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2.111, σ z 2 = 0.064. (25 points).
13. In randomly selected 100 ears of winter wheat, the number of spikelets was counted. The sample set was characterized by the following indicators:
 = 15 spikelets and σ = 2.28 pcs. Determine the accuracy with which the average result is obtained (
= 15 spikelets and σ = 2.28 pcs. Determine the accuracy with which the average result is obtained (  ) and plot the confidence interval for the overall mean and variance at 95% and 99% significance levels (30 points).
) and plot the confidence interval for the overall mean and variance at 95% and 99% significance levels (30 points).
14. The number of ribs on the shells of a fossil mollusk Orthambonites calligramma:
It is known that n = 19, σ = 4.25. Determine the boundaries of the confidence interval for the general mean and general variance at a significance level W = 0.01 (25 points).
15. To determine milk yields on a commercial dairy farm, the productivity of 15 cows was determined daily. According to the data for the year, each cow gave on average the following amount of milk per day (l): 22; nineteen; 25; 20; 27; 17; thirty; 21; eighteen; 24; 26; 23; 25; 20; 24. Plot confidence intervals for the general variance and the arithmetic mean. Can we expect the average annual milk yield per cow to be 10,000 liters? (50 points).
16. In order to determine the average wheat yield for the farm, mowing was carried out on sample plots of 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 and 2 ha. The yield (c/ha) from the plots was 39.4; 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; 29 respectively. Plot confidence intervals for the general variance and the arithmetic mean. Is it possible to expect that the average yield for the agricultural enterprise will be 42 c/ha? (50 points).
The confidence interval came to us from the field of statistics. This is a defined range that serves to estimate an unknown parameter with a high degree reliability. The easiest way to explain this is with an example.
Suppose you need to investigate some random variable, for example, the speed of the server's response to a client request. Each time a user types in the address of a particular site, the server responds at a different rate. Thus, the investigated response time has a random character. So, the confidence interval allows you to determine the boundaries of this parameter, and then it will be possible to assert that with a probability of 95% the server will be in the range we calculated.
Or you need to find out how many people know about trademark firms. When the confidence interval is calculated, it will be possible, for example, to say that with a 95% probability the share of consumers who know about this is in the range from 27% to 34%.
Closely related to this term is such a value as the confidence level. It represents the probability that the desired parameter is included in the confidence interval. This value determines how large our desired range will be. How greater value it accepts, the narrower the confidence interval becomes, and vice versa. Usually it is set to 90%, 95% or 99%. The value of 95% is the most popular.
On the this indicator the variance of observations also has an effect and its definition is based on the assumption that the feature under study obeys. This statement is also known as Gauss' Law. According to him, such a distribution of all probabilities of a continuous random variable, which can be described by the probability density. If the assumption of a normal distribution turned out to be wrong, then the estimate may turn out to be wrong.
First, let's figure out how to calculate the confidence interval for Here, two cases are possible. Dispersion (the degree of spread of a random variable) may or may not be known. If it is known, then our confidence interval is calculated using the following formula:
xsr - t*σ / (sqrt(n))<= α <= хср + t*σ / (sqrt(n)), где
α - sign,
t is a parameter from the Laplace distribution table,
σ is the square root of the dispersion.
If the variance is unknown, then it can be calculated if we know all the values of the desired feature. For this, the following formula is used:
σ2 = х2ср - (хр)2, where
х2ср - the average value of the squares of the trait under study,
(xsr)2 is the square of this feature.
The formula by which the confidence interval is calculated in this case changes slightly:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n)), где
xsr - sample mean,
α - sign,
t is a parameter that is found using the Student's distribution table t \u003d t (ɣ; n-1),
sqrt(n) is the square root of the total sample size,
s is the square root of the variance.
Consider this example. Assume that, based on the results of 7 measurements, the trait under study was determined to be 30 and the sample variance equal to 36. It is necessary to find a confidence interval with a probability of 99% that contains the true value of the measured parameter.
First, let's determine what t is equal to: t \u003d t (0.99; 7-1) \u003d 3.71. Using the above formula, we get:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (sqrt(7))<= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
The confidence interval for the variance is calculated both in the case of a known mean and when there is no data on the mathematical expectation, and only the value of the unbiased point estimate of the variance is known. We will not give here the formulas for its calculation, since they are quite complex and, if desired, they can always be found on the net.
We only note that it is convenient to determine the confidence interval using the Excel program or a network service, which is called so.

