Если частный коэффициент детерминации отрицательное число. Расчет коэффициента детерминации в Microsoft Excel
Вариация признака определяется различными факторами, часть этих факторов можно выделить, если статистическую совокупность разделить на группы по определенному признаку. Тогда, наряду с изучением вариации признака по совокупности в целом, можно изучить вариацию для каждой из составляющих ее группы и между этими группами. В простом случае, когда совокупность разделена на группы по одному фактору, изучение вариации достигается посредством вычисления и анализа трех видов дисперсий: общей, межгрупповой и внутригрупповой.
Эмпирический коэффициент детерминации
Эмпирический коэффициент детерминации широко применяется в статистическом анализе и является показателем, представляющим долю межгруппопой дисперсии в результативного признака и характеризует силу влияния группировочного признака на образование общей вариации. Он может быть рассчитан по формуле:
Показывает долю вариации результативного признака у под влиянием факторного признака х, он связан с коэффициентом корреляции квадратичной зависимостью. При отсутствии связи эмпирический коэффициент детерминации равен нулю, а при функциональной связи - единице.
Например, когда изучается зависимость производительности труда рабочих от их квалификации коэффициент детерминации равен 0,7, то на 70% вариация производительности труда рабочих обусловлена различиями в их квалификации и на 30% - влиянием прочих факторов.
Эмпирическое корреляционное отношение - это квадратный корень из коэффициента детерминации. Отношение показывает тесноту связи между группировочным и результативным признаками. Эмпирическое корреляционное отношение принимает значения от -1 до 1. Если связи нет, то корреляционное отношение равняется нулю, т.е. все групповые средние равняются между собой и межгрупповой вариации нет. Значит, группировочный признак не влияет на образование общей вариации.
Если связь функциональная, то корреляционное отношение равняется единице. В таком случае дисперсия групповых средних равна общей дисперсии, т.е. внутригрупповой вариации нет. Это значит, что группировочный признак полностью определяет вариацию результативного признака.
Чем ближе значение корреляционного отношения к единице, тем сильнее и ближе к функциональной зависимости связь между признаками. Для качественной оценки силы связи на основе показателя эмпирического коэффициента корреляции можно использовать соотношение Чэддока.
Соотношение Чэддока
- Связь весьма тесная — коэффициент корреляции находится в интервале 0,9 — 0,99
- Связь тесная — Rxy = 0,7 — 0,9
- Связь заметная — Rxy = 0,5 — 0,7
- Связь умеренная — Rxy = 0,3 — 0,5
- Связь слабая — Rxy = 0,1 — 0,3
Рассмотрим вначале коэффициент детерминации для простой линейной регрессии, называемый также коэффициентом парной детерминации.
На основе соображений, изложенных в разделе 3.1, теперь относительно легко найти меру точности оценки регрессии. Мы показали, что общую дисперсию можно разложить на две составляющие - на «необъясненную» дисперсию и дисперсию обусловленную регрессией. Чем больше по сравнению с тем больше общая дисперсия формируется за счет влияния объясняющей переменной х и, следовательно, связь между двумя переменными у их более интенсивная. Очевидно, удобно в качестве показателя интенсивности связи, или оценки доли влияния переменной х на использовать отношение

Это отношение указывает, какая часть общего (полного) рассеяния значений у обусловлена изменчивостью переменной х. Чем большую долю в общей дисперсии составляет тем лучше выбранная функция регрессии соответствует эмпирическим данным. Чем меньше эмпирические значения зависимой переменной отклоняются от прямой регрессии, тем лучше определена функция регрессии. Отсюда происходит и название отношения (3.6) - коэффициент детерминации Индекс при коэффициенте указывает на переменные, связь между которыми изучается. При этом вначале в индексе стоит обозначение зависимой переменной, а затем объясняющей.
Из определения коэффициента детерминации как относительной доли очевидно, что он всегда заключен в пределах от 0 до 1:
![]()
Если то все эмпирические значения (все точки поля корреляции) лежат на регрессионной прямой. Это означает, что для В этом случае говорят о строгом линейном соотношении (линейной функции) между переменными у их. Если дисперсия, обусловленная регрессией, равна нулю, а
«необъясненная» дисперсия равна общей дисперсии. В этом случае Линия регрессии тогда параллельна оси абсцисс. Ни о какой численной линейной зависимости переменной у от в статистическом ее понимании не может быть и речи. Коэффициент регрессии при этом незначимо отличается от нуля.
Итак, чем больше приближается к единице, тем лучше определена регрессия.
Коэффициент детерминации есть величина безразмерная и поэтому он не зависит от изменения единиц измерения переменных у и х (в отличие от параметров регрессии). Коэффициент не реагирует на преобразование переменных.
Приведем некоторые модификации формулы (3.6), которые, с одной стороны, будут способствовать пониманию сущности коэффициента детерминации, а с другой стороны, окажутся полезными для практических вычислений. Подставляя выражение для в (3.6) и принимая во внимание (1.8) и (3.1), получим:
![]()
Эта формула еще раз подтверждает, что «объясненная» дисперсия, стоящая в числителе (3.6), пропорциональна дисперсии переменной х, так как является оценкой параметра регрессии.
Подставив вместо его выражение (2.26) и учитывая определения дисперсий а также средних х и у, получим формулу коэффициента детерминации, удобную для вычисления:


Из (3.9) следует, что всегда С помощью (3.9) можно относительно легко определить коэффициент детерминации. В этой формуле содержатся только те величины, которые используются для вычисления оценок параметров регрессии и, следовательно, имеются в рабочей таблице. Формула (3.9) обладает тем преимуществом, что вычисление коэффициента детерминации по ней производится непосредственно по эмпирическим данным. Не нужно заранее находить оценки параметров и значения регрессии. Это обстоятельство играет немаловажную роль для последующих исследований, так как перед проведением регрессионного анализа мы можем проверить, в какой степени определена исследуемая регрессия включенными в нее объясняющими
переменными. Если коэффициент детерминации слишком мал, то нужно искать другие факторы-переменные, причинно обусловливающие зависимую переменную. Следует отметить, что коэффициент детерминации удовлетворительно отвечает своему назначению при достаточно большом числе наблюдений. Но в любом случае необходимо проверить значимость коэффициента детерминации. Эта проблема будет обсуждаться в разделе 8.6.
Вернемся к рассмотрению «необъясненной» дисперсии, возникающей за счет изменчивости прочих факторов-переменных, не зависящих от х, а также за счет случайностей. Чем больше ее доля в общей дисперсии, тем меньше, неопределеннее проявляется соотношение между у и х, тем больше затушевывается связь между ними. Исходя из этих соображений мы можем использовать «необъясненную» дисперсию для характеристики неопределенности или неточности регрессии. Следующее соотношение служит мерой неопределенности регрессии:

Легко убедиться в том, что
![]()
![]()
Отсюда очевидно, что не нужно отдельно вычислять меру неопределенности, а ее оценку легко получить из (3.11).
Теперь вернемся к нашим примерам и определим коэффициенты детерминации для полученных уравнений регрессий.
Вычислим коэффициент детерминации по данным примера из раздела 2.4 (зависимость производительности труда от уровня механизации работ). Используем для этого формулу (3.9), а промежуточные результаты вычислений заимствуем из табл. 3:
Отсюда заключаем, что в случае простой регрессии 93,8% общей дисперсии производительности труда на рассматриваемых предприятиях обусловлено вариацией показателя механизации работ. Таким образом, изменчивость переменной х почти полностью объясняет вариацию переменной у.
Для этого примера коэффициент неопределенности т. е. только 6,2% общей дисперсии нельзя объяснить зависимостью производительности труда от уровня механизации работ.
Вычислим коэффициент детерминации по данным примера из раздела 2.5 (зависимость объема производства от основных фондов). Необходимые
промежуточные результаты вычислений приведены в разделе 2.5 при определении оценок коэффициентов регрессии:
Таким образом, 91,1% общей дисперсии объема производства исследуемых предприятий обусловлено изменчивостью значений основных фондов на этих предприятиях. Данная регрессия почти полностью исчерпывается включенной в нее объясняющей переменной. Коэффициент неопределенности составляет 0,089, или 8,9%.
Следует отметить, что приведенные в данном разделе формулы предназначены для вычисления по результатам выборки большого объема коэффициента детерминации в случае простой регрессии. Но чаще всего приходится довольствоваться выборкой небольшого объема . В этом случае вычисляют исправленный коэффициент детерминации учитывая соответствующее число степеней свободы. Формула исправленного коэффициента детерминации для общего случая объясняющих переменных будет приведена в следующем разделе. Из нее легко получить формулу исправленного коэффициента детерминации в случае простой регрессии
Коэффициент детерминации
Для оценки качества подбора линейной функции (близости расположения фактических данных к рассчитанной линии регрессии) рассчитывается квадрат линейного коэффициента корреляции , называемый коэффициентом детерминации.
Проверка осуществляется на основе исследования коэффициента детерминации и проведения дисперсионного анализа.
Регрессионная модель показывает, что вариация Y может быть объяснена вариацией независимой переменной Х и значением возмущения e. Мы хотим знать, насколько вариация Y обусловлена изменением Х и насколько она является следствием случайных причин. Другими словами, нам нужно знать, насколько хорошо рассчитанное уравнение регрессии соответствует фактическим данным, т.е. насколько мала вариация данных вокруг линии регрессии.
Для оценки степени соответствия линии регрессии нужно рассчитать коэффициент детерминации, суть которого можно хорошо уяснить, рассматривая разложение общей суммы квадратов отклонений переменной Y от среднего значения на две части – «объясненную» и «необъясненную» (рис. 4).
Из рис. 4 видно, что ![]() .
.
Возведем обе части этого равенства в квадрат и просуммируем по всем i от 1 до n .
Перепишем сумму произведений в виде:

Здесь использованы следующие свойства:
2) метод наименьших квадратов (МНК)исходит из условия:
необходимым условием существования минимума функции Q является равенство нулю ее первых частных производных по b 0 и b 1 .
![]() .
.
Или ![]() .
.
Отсюда следует, что .
 |
 |
 Y i
Y i

 |
|||||
Рисунок 4. Структура вариации зависимой переменной Y
Таким образом, в результате будем иметь:
 (1)
(1)
Общая сумма квадратов отклонений индивидуальных значений зависимой переменной Y от среднего значения вызвана влиянием множества причин, которые мы условно разделили на две группы: фактор Х и прочие факторы (случайные воздействия). Если фактор Х не оказывает влияния на результат (Y), то линия регрессии на графике параллельна оси абсцисс и . Тогда вся дисперсия зависимой переменной Y обусловлена воздействием прочих факторов, и общая сумма квадратов отклонений совпадает с остаточной суммой квадратов. Если же прочие факторы не влияют на результат, то Y связан с Х функционально, и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объясненная регрессией, совпадает с общей суммой квадратов.
Разделим обе части уравнения (1) на левую часть (на общую сумму квадратов), получим:
 (2)
(2)
Доля дисперсии зависимой переменной, объясненная регрессией, называется коэффициентом детерминации и обозначается R 2 . Из (2) коэффициент детерминации определяется:
 . (3)
. (3)
Величина коэффициента детерминации находится в пределах от 0 до 1 и служит одним из критериев проверки качества линейной модели. Чем больше доля объясненной вариации, тем соответственно меньше роль прочих факторов, следовательно, линейная модель хорошо аппроксимирует исходные данные, и ею можно пользоваться для прогноза значений результативного признака.
коэффициент детерминации принимает значения от нуля, когда х не влияют на У, до единицы, когда изменение У полностью объясняется изменением х . Таким образом, коэффициент детерминации характеризует «полноту» модели.
Преимущества коэффициента детерминации: он легко вычисляется, интуитивно понятен и имеет четкую интерпретацию. Но несмотря на это его использование иногда связано с проблемами:
· нельзя сравнивать величины R 2 для моделей с различными зависимыми переменными;
· R 2 всегда возрастает по мере включения новых переменных в модель. Это свойство R 2 может создавать у исследователя стимул необоснованно включать дополнительные переменные в модель, и в любом случае становится проблематичным определить, улучшает ли дополнительная переменная качество модели;
· R 2 малопригоден для оценки качества моделей временных рядов, т.к. в таких моделях его значение часто достигает величины 0,9 и выше; дифференциация моделей на основании данного коэффициента является трудновыполнимой задачей.
Одна из перечисленных проблем – увеличение R 2 при введении в модель дополнительных переменных – решается путем коррекции коэффициента на уменьшение числа степеней свободы в результате появления в модели дополнительных переменных.
Скорректированный коэффициент детерминации рассчитывается так:
![]() , (4)
, (4)
Как видно из формулы, при добавлении переменных будет увеличиваться только в том случае, если рост R 2 будет «перевешивать» увеличение количества переменных. Действительно,
т.е. доля остаточной дисперсии с включением новых переменных должна уменьшаться, но, умноженная на она, в то же время, будет расти с ростом числа включенных в модель переменных (р); в итоге, если положительный эффект от включения новых факторов «перевесит» изменение числа степеней свободы, то увеличится; в противном случае – может и уменьшиться.
Оценка качества уравнения (адекватности выбранной модели эмпирическим данным) производится с помощью F-теста. Суть оценки сводится к проверке нулевой гипотезы Н 0 о статистической незначимости уравнения регрессии и коэффициента детерминации. Для этого выполняется сравнение фактического F факт и критического (табличного) F табл значений F-критерия Фишера:
![]() . (5)
. (5)
В случае справедливости гипотезы
Н 0: b 0 = b 1 = … = b р = 0 (или R 2 истин = 0)
статистика F факт должна подчиняться F – распределению с числом степеней свободы числителя и знаменателя, соответственно равными
n 1 = р и n 2 = n – p – 1.
Табличное значение F-критерия для вероятности 0,95 (или 0,99) и числа степеней свободы n 1 = р, n 2 = n – p – 1 сравнивается с вычисленным; при выполнении неравенства F > F табл отвергается нулевая гипотеза о том, что истинное значение коэффициента детерминации равно нулю; это дает основание считать, что модель адекватна исследуемому процессу.
Для парной модели в критерии проверки для R 2 числителю соответствует одна степень свободы и (n – 2) степеней свободы соответствует знаменателю. Расчет F-критерия для проверки значимости R 2 выполняется следующим образом:
 .
.
Обратившись к F-таблице, видим, что табличное значение при 5%-м уровне значимости для n 1 = 1 и n 2 = 50 составляет примерно 4. Так как расчетное значение F-критерия больше табличного, то при доверительной вероятности 0,95 отвергаем нулевую гипотезу о том, что истинное значение коэффициента детерминации равно нулю.
Таким образом, можно сделать вывод о том, что коэффициент детерминации (а значит, и модель в целом) являются статистически надежным показателем взаимосвязи рассматриваемых фондовых индексов.
Квадратный корень из величины коэффициента детерминации для парной модели является коэффициентом корреляции – показателем тесноты связи.
Третья стадия – проверка выполнимости основных предпосылок классической регрессии – предмет дальнейшего изучения .
Коэффициент детерминации
Коэффициент детерминации ( - R-квадрат ) - это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью зависимости, то есть объясняющими переменными. Более точно - это единица минус доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной по факторам дисперсии зависимой переменной) в дисперсии зависимой переменной. Его рассматривают как универсальную меру связи одной случайной величины от множества других. В частном случае линейной зависимости является квадратом так называемого множественного коэффициента корреляции между зависимой переменной и объясняющими переменными. В частности, для модели парной линейной регрессии коэффициент детерминации равен квадрату обычного коэффициента корреляции между y и x .
Определение и формула
Истинный коэффициент детерминации модели зависимости случайной величины y от факторов x определяется следующим образом:
где - условная (по факторам x) дисперсия зависимой переменной (дисперсия случайной ошибки модели).
В данном определении используются истинные параметры, характеризующие распределение случайных величин. Если использовать выборочную оценку значений соответствующих дисперсий, то получим формулу для выборочного коэффициента детерминации (который обычно и подразумевается под коэффициентом детерминации):
где -сумма квадратов остатков регрессии, - фактические и расчетные значения объясняемой переменной.
Общая сумма квадратов.
В случае линейной регрессии с константой , где - объяснённая сумма квадратов, поэтому получаем более простое определение в этом случае - коэффициент детерминации - это доля объяснённой суммы квадратов в общей :
Необходимо подчеркнуть, что эта формула справедлива только для модели с константой, в общем случае необходимо использовать предыдущую формулу.
Интерпретация
1. Коэффициент детерминации для модели с константой принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это интерпретируется как соответствие модели данным. Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 50% (в этом случае коэффициент множественной корреляции превышает по модулю 70%). Модели с коэффициентом детерминации выше 80% можно признать достаточно хорошими (коэффициент корреляции превышает 90%). Значение коэффициента детерминации 1 означает функциональную зависимость между переменными.
2. При отсутствии статистической связи между объясняемой переменной и факторами, статистика для линейной регрессии имеет асимптотическое распределение , где - количество факторов модели (см. тест множителей Лагранжа). В случае линейной регрессии с нормально распределёнными случайными ошибками статистика имеет точное (для выборок любого объёма) распределение Фишера (см. F-тест). Информация о распределении этих величин позволяет проверить статистическую значимость регрессионной модели исходя из значения коэффициента детерминации. Фактически в этих тестах проверяется гипотеза о равенстве истинного коэффициента детерминации нулю.
Недостаток и альтернативные показатели
Основная проблема применения (выборочного) заключается в том, что его значение увеличивается (не уменьшается) от добавления в модель новых переменных, даже если эти переменные никакого отношения к объясняемой переменной не имеют! Поэтому сравнение моделей с разным количеством факторов с помощью коэффициента детерминации, вообще говоря, некорректно. Для этих целей можно использовать альтернативные показатели.
Скорректированный (adjusted)
Для того, чтобы была возможность сравнивать модели с разным числом факторов так, чтобы число регрессоров (факторов) не влияло на статистику обычно используется скорректированный коэффициент детерминации , в котором используются несмещённые оценки дисперсий:
который даёт штраф за дополнительно включённые факторы, где n - количество наблюдений, а k - количество параметров.
Данный показатель всегда меньше единицы, но теоретически может быть и меньше нуля (только при очень маленьком значении обычного коэффициента детерминации и большом количестве факторов). Поэтому теряется интерпретация показателя как "доли". Тем не менее, применение показателя в сравнении вполне обоснованно.
Для моделей с одинаковой зависимой переменной и одинаковым объемом выборки сравнение моделей с помощью скорректированного коэффициента детерминации эквивалентно их сравнению с помощью остаточной дисперсии или стандартной ошибки модели . Разница только в том, что последние критерии чем меньше, тем лучше.
Информационные критерии
AIC
- информационный критерий Акаике - применяется исключительно для сравнения моделей. Чем меньше значение тем лучше. Часто используется для сравнения моделей временных рядов с разным количеством лагов.
, где k
- количество параметров модели.
BIC
или SC
- байесовский информационный критерий Шварца - используется и интерпретируется аналогично AIC.
. Даёт больший штраф за включение лишних лагов в модель, чем AIC.
-обобщённый (extended)
В случае отсутствия в линейной множественной МНК регрессии константы свойства коэффициента детерминации могут нарушаться для конкретной реализации . Поэтому модели регрессии со свободным членом и без него нельзя сравнивать по критерию . Эта проблема решается с помощью построения обобщённого коэффициента детерминации , который совпадает с исходным для случая МНК регрессии со свободным членом, и для которого выполняются четыре свойства перечисленные выше. Суть этого метода заключается рассмотрении проекции единичного вектора на плоскость объясняющих переменных.
Для случая регрессии без свободного члена:
,
где X - матрица nxk значений факторов, - проектор на плоскость X, , где - единичный вектор nx1.
с условием небольшой модификации , также подходит для сравнения между собой регрессий построенных с помощью: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК).
Замечание
Высокие значения коэффициента детерминации, вообще говоря, не свидетельствуют о наличии причинно-следственной зависимости между переменными (также как и в случае обычного коэффициента корреляции). Например, если объясняемая переменная и факторы, на самом деле не связанные с объясняемой переменой, имеют возрастающую динамику, то коэффициент детерминации будет достаточно высок. Поэтому логическая и смысловая адекватность модели имеют первостепенную важность. Кроме того, необходимо использовать критерии для всестороннего анализа качества модели.
См. также
Примечания
Ссылки
- Прикладная эконометрика (журнал)
Wikimedia Foundation . 2010 .
- Коэффициент де Ритиса
- Коэффициент естественной освещённости
Смотреть что такое "Коэффициент детерминации" в других словарях:
КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ - оценка качества (объясняющей способности) уравнения регрессии, доля дисперсии объясненной зависимой переменной у: R2= 1 Sum(yi yzi)2 / Sum(yi y)2 , где yi наблюдаемое значение зависимой переменной y, yzi значение зависимой переменной,… … Социология: Энциклопедия
Коэффициент детерминации - квадрат коэффициента линейной корреляции Пирсона, интерпретируется как доля дисперсии зависимой переменной, объясненной посредством независимой переменной … Социологический словарь Socium
Коэффициент детерминации - Мера того, насколько хорошо соотносятся зависимые и независимые переменные в регрессивном анализе. Например, процент от изменения доходности актива, объясняемый доходностью рыночного портфеля … Инвестиционный словарь
Коэффициент детерминации - (COEFFICIENT OF DETERMINATION) определяется при построении линейной регрессионной зависимости. Равен доле дисперсии зависимой переменной, связанной с вариаций независимой переменной … Финансовый глоссарий
Коэффициент корреляции - (Correlation coefficient) Коэффициент корреляции это статистический показатель зависимости двух случайных величин Определение коэффициента корреляции, виды коэффициентов корреляции, свойства коэффициента корреляции, вычисление и применение… … Энциклопедия инвестора
В пунктах 3.3, 4.1рассмотрена постановка задачи оценивания уравнения линейной регрессии, показан способ ее решения. Однако оценка параметров конкретного уравнения является лишь отдельным этапом длительного и сложного процесса построения эконометрической модели.Первое же оцененное уравнение очень редко является удовлетворительным во всех отношениях. Обычно приходится постепенно подбирать формулу связи и состав объясняющих переменных, анализируя на каждом этапе качество оцененной зависимости. Этот анализ качества включает статистическую и содержательную составляющую. Проверка статистического качества оцененного уравнения состоит из следующих элементов:
проверка статистической значимости каждого коэффициента уравнения регрессии;
проверка общего качества уравнения регрессии;
проверка свойств данных, выполнение которых предполагалось
при оценивании уравнения.
Под содержательной составляющей анализа качества понимается рассмотрение экономического смысла оцененного уравнения регрессии: действительно ли значимыми оказались объясняющие факторы, важные с точки зрения теории; положительны или отрицательны коэффициенты, показывающие направление воздействия этих факторов; попали ли оценки коэффициентов регрессии в предполагаемые из теоретических соображений интервалы.
Методика проверки статистической значимости каждого отдельного коэффициента уравнения линейной регрессии была рассмотрена в предыдущей главе. Перейдем теперь к другим этапам проверки качества уравнения.
4.2.1. Проверка общего качества уравнения регрессии. Коэффициент детерминации r2
Для анализа общего качества оцененной линейной регрессии используют обычно коэффициент детерминации R 2 . Для случая парной регрессии это квадрат коэффициента корреляции переменныхх иy . Коэффициент детерминации рассчитывается по формуле
Коэффициент детерминации характеризует долю вариации (разброса) зависимой переменной, объясненной с помощью данного уравнения. В качестве меры разброса зависимой переменной обычно используется ее дисперсия, а остаточная вариация может быть измерена как дисперсия отклонений вокруг линии регрессии. Если числитель и знаменатель вычитаемой из единицы дроби разделить на число наблюденийп, то получим, соответственно, выборочные оценки остаточной дисперсии и дисперсии зависимой переменнойу. Отношение остаточной и общей дисперсий представляет собой долю необъясненной дисперсии. Если же эту долю вычесть из единицы, то получим долю дисперсии зависимой переменной, объясненной с помощью регрессии. Иногда при расчете коэффициента детерминации для получения несмещенных оценок дисперсии в числителе и знаменателе вычитаемой из единицы дроби делается поправка на число степеней свободы; тогда
 .
.
или, для парной регрессии, где число независимых переменных т равно 1,

В числителе дроби, которая вычитается
из единицы, стоит сумма квадратов
отклонений наблюдений у
i
от линии регрессии, в знаменателе - от
среднего значения переменнойу.
Таким образом,дробь эта мала (а
коэффициент
R
2
,
очевидно, близок к единице), если разброс
точек вокруг линии регрессии значительно
меньше, чем вокруг среднего значения
.
МНК позволяет найти прямую, для которой
суммае
i
2
минимальна, а представляет
собой одну из возможных линий, для
которых выполняется условие.
Поэтому величина в числителе вычитаемой
из единицы дроби меньше, чем величина
в ее знаменателе, - иначе выбиремой по
МНК линией регрессии была бы прямая
представляет
собой одну из возможных линий, для
которых выполняется условие.
Поэтому величина в числителе вычитаемой
из единицы дроби меньше, чем величина
в ее знаменателе, - иначе выбиремой по
МНК линией регрессии была бы прямая .
Таким образом, коэффициент детерминацииR
2
является мерой,
позволяющей определить, в какой степени
найденная регрессионная прямая дает
лучший результат для объяснения поведения
зависимой переменнойу,
чем просто
горизонтальная прямая
.
Таким образом, коэффициент детерминацииR
2
является мерой,
позволяющей определить, в какой степени
найденная регрессионная прямая дает
лучший результат для объяснения поведения
зависимой переменнойу,
чем просто
горизонтальная прямая .
.
Смысл коэффициента детерминации может
быть пояснен и немного иначе. Можно
показать, что
 ,
гдеk
i
=
,
гдеk
i
= - отклонениеi
‑
й
точки на линии регрессии от
- отклонениеi
‑
й
точки на линии регрессии от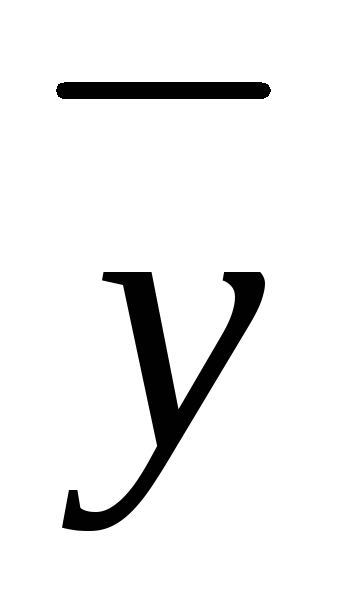 .
В данной формуле величина в левой части
может интерпретироваться как мера
общего разброса (вариации) переменнойу,
первое слагаемое в правой части
.
В данной формуле величина в левой части
может интерпретироваться как мера
общего разброса (вариации) переменнойу,
первое слагаемое в правой части -
как мера разброса, объясненного с помощью
регрессии, и второе слагаемое
-
как мера разброса, объясненного с помощью
регрессии, и второе слагаемое -
как мера остаточного, необъясненного
разброса (разброса точек вокруг линии
регрессии). Если разделить эту формулу
на ее левую часть и перегруппировать
члены, то
-
как мера остаточного, необъясненного
разброса (разброса точек вокруг линии
регрессии). Если разделить эту формулу
на ее левую часть и перегруппировать
члены, то
 ,
то есть коэффициент детерминацииR
2 есть доля объясненной части разброса
зависимой переменной (или доля объясненной
дисперсии, если разделить числитель и
знаменатель наn
илип-
1).
Часто коэффициент детерминацииR
2
иллюстрируют рис.
4.2
,
то есть коэффициент детерминацииR
2 есть доля объясненной части разброса
зависимой переменной (или доля объясненной
дисперсии, если разделить числитель и
знаменатель наn
илип-
1).
Часто коэффициент детерминацииR
2
иллюстрируют рис.
4.2

Рис. 4.2.
Здесь TSS (To tal Sum of Squares ) - общий разброс переменнойу, Е SS (Explained Sum of Squares ) - разброс, объясненный с помощью регрессии, USS (Unexplained Sum of Squares ) -разброс, необъясненный с помощью регрессии. Из рисунка видно, что с увеличением объясненной доли разброса коэффициентR 2 - приближается к единице. Кроме того, из рисунка видно, что с добавлением еще одной переменнойR 2 обычно увеличивается, однако если объясняющие переменныех 1 их 2 сильно коррелируют между собой, то они объясняют одну и ту же часть разброса переменнойу, и в этом случае трудно идентифицировать вклад каждой из переменных в объяснение поведенияу.
Если существует статистически значимая линейная связь величин х иу , то коэффициентR 2 близок к единице. Однако он может быть близким к единице просто в силу того, что обе эти величины имеют выраженный временной тренд, не связанный с их причинно-следственной взаимозависимостью. В экономике обычно объемные показатели (доход, потребление, инвестиции) имеют такой тренд, а темповые и относительные (производительности, темпы роста, доли, отношения) - не всегда. Поэтому при оценивании линейных регрессий по временным рядам объемных показателей (например, зависимости выпуска от затрат ресурсов или объема потребления от величины дохода) величинаR 2 обычно очень близка к единице. Это говорит о том, что зависимую переменную нельзя описать просто как равную своему среднему значению, но это и заранее очевидно, раз она имеет временной тренд.
Если имеются не временные ряды, а перекрестная выборка, то есть данные об однотипных объектах в один и тот же момент времени, то для оцененного по ним уравнения линейной регрессии величина R 2 не превышает обычно уровня 0,6-0,7. То же самое обычно имеет место и для регрессии по временным рядам, если они не имеют выраженного тренда. В макроэкономике примерами таких зависимостей являются связи относительных, удельных, темповых показателей: зависимость темпа инфляции от уровня безработицы, нормы накопления от величины процентной ставки, темпа прироста выпуска от темпов прироста затрат ресурсов. Таким образом, при построении макроэкономических моделей, особенно - по временным рядам данных, нужно учитывать, являются входящие в них переменные объемными или относительными, имеют ли они временной тренд 1 .
Точную границу приемлемости показателя
R
2 указать сразу для всех
случаев невозможно. Нужно принимать во
внимание и число степеней свободы
уравнения, и наличие трендов переменных,
и содержательную интерпретацию уравнения.
ПоказательR
2
может
оказаться даже отрицательным. Как
правило, это случается в уравнении без
свободного членау = .
Оценивание такого уравнения производится,
как и в общем случае, по методу наименьших
квадратов. Однако множество выбора при
этом существенно сужается: рассматриваются
не все возможные прямые или гиперплоскости,
а только проходящие через начало
координат. ВеличинаR
2
получится отрицательной в том случае,
если разброс значений зависимой
переменной вокруг прямой (гиперплоскости)
.
Оценивание такого уравнения производится,
как и в общем случае, по методу наименьших
квадратов. Однако множество выбора при
этом существенно сужается: рассматриваются
не все возможные прямые или гиперплоскости,
а только проходящие через начало
координат. ВеличинаR
2
получится отрицательной в том случае,
если разброс значений зависимой
переменной вокруг прямой (гиперплоскости) меньше, чем вокруг даже наилучшей прямой
(гиперплоскости) из проходящих через
начало координат. Отрицательная величинаR
2
в уравнении
меньше, чем вокруг даже наилучшей прямой
(гиперплоскости) из проходящих через
начало координат. Отрицательная величинаR
2
в уравнении
 говорит
о целесообразности введения в него
свободного члена. Эта ситуация
проиллюстрирована на рис. 4.3.
говорит
о целесообразности введения в него
свободного члена. Эта ситуация
проиллюстрирована на рис. 4.3.
Линия 1 на нем - график уравнения регрессии
без свободного члена (он проходит через
начало координат), линия 2 - со свободным
членом (он равен а
0
), линия
3 - .
Горизонтальная линия 3 дает гораздо
меньшую сумму квадратов отклоненийе
i
,
чем линия 1, и поэтому для последней
коэффициент детерминацииR
2 будет отрицательным.
.
Горизонтальная линия 3 дает гораздо
меньшую сумму квадратов отклоненийе
i
,
чем линия 1, и поэтому для последней
коэффициент детерминацииR
2 будет отрицательным.

Рис. 4.3. Линии уравнений линейной регрессии у=f(х) без свободного члена (1) и со свободным членом (2)
Поправка на число степеней свободы всегда уменьшает значение R 2 , поскольку(п- 1)>(п-т- 1). В результате величинаR 2 также может стать отрицательной. Но это означает, что она была близкой к нулю до такой поправки, и объясненная с помощью уравнения регрессии доля дисперсии зависимой переменной очень мала.

