Оценка значимости уравнения регрессии и его коэффициентов. Оценка статистической значимости уравнения регрессии его параметров
С помощью МНК можно получить лишь оценки параметров уравнения регрессии. Чтобы проверить, значимы ли параметры (т.е. значимо ли они отличаются от нуля в истинном уравнении регрессии) используют статистические методы проверки гипотез. В качестве основной гипотезы выдвигают гипотезу о незначимом отличии от нуля параметра регрессии или коэффициента корреляции. Альтернативной гипотезой, при этом является гипотеза обратная, т.е. о неравенстве нулю параметра или коэффициента корреляции. Для проверки гипотезы используется t- критерий Стьюдента.
Найденное по данным наблюдений значение t- критерия (его еще называют наблюдаемым или фактическим) сравнивается с табличным (критическим) значением, определяемым по таблицам распределения Стьюдента (которые обычно приводятся в конце учебников и практикумов по статистике или эконометрике). Табличное значение определяется в зависимости от уровня значимости и числа степеней свободы, которое в случае линейной парной регрессии равно , n -число наблюдений.
Если фактическое значение t -критерия больше табличного (по модулю), то считают, что с вероятностью параметр регрессии (коэффициент корреляции) значимо отличается от нуля.
Если фактическое значение t -критерия меньше табличного (по модулю), то нет оснований отвергать основную гипотезу, т.е. параметр регрессии (коэффициент корреляции) незначимо отличается от нуля при уровне значимости .
Фактические значения t -критерия определяются по формулам:
![]() ,
,
![]() ,
,
где  .
.
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции используют критерий:
где r - оценка коэффициента корреляции, полученная по наблюдаемым данным.
Прогноз ожидаемого значения результативного признака Y по линейному парному уравнению регрессии.
Пусть требуется оценить прогнозное значение признака-результата для заданного значения признака-фактора . Прогнозируемое значение признака-результата с доверительной вероятностью равной принадлежит интервалу прогноза:
![]() ,
,
где - точечный прогноз;
t - коэффициент доверия, определяемый по таблицам распределения Стьюдента в зависимости от уровня значимости α и числа степеней свободы ;
Средняя ошибка прогноза.
Точечный прогноз рассчитывается по линейному уравнению регрессии, как:
![]() .
.
Средняя ошибка прогноза определяется по формуле:
 .
.
Пример 1.
На основе данных, приведенных в Приложении и соответствующих варианту 100, требуется:
1. Построить уравнение линейной парной регрессии одного признака от другого. Один из признаков, соответствующих Вашему варианту, будет играть роль факторного (Х), другой - результативного . Причинно-следственные связи между признаками установить самим на основе экономического анализа. Пояснить смысл параметров уравнения.
3. Оценить статистическую значимость параметров регрессии и коэффициента корреляции с уровнем значимости 0,05.
4. Выполнить прогноз ожидаемого значения признака-результата Yпри прогнозном значении признака-фактора X, составляющим 105% от среднего уровня X. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал с вероятностью 0,95.
Решение:
В качестве признака-фактора в данном случае выберем курсовую цену акций, так как от прибыльности акций зависит величина начисленных дивидендов. Таким образом, результативным будет признак дивиденды, начисленные по результатам деятельности .
Для облегчения расчетов построим расчетную таблицу, которая заполняется по ходу решения задачи. (Таблица 1)
Для наглядности зависимости Yот X представим графически. (Рисунок 2)

Таблица 1 - Расчетная таблица

1. Построим уравнение регрессии вида: .
Для этого необходимо определить параметры уравнения и .
Определим  ,
,
где - среднее из значений , возведенных в квадрат;
Среднее значение в квадрате.
Определим параметр а 0 :
Получим уравнение регрессии следующего вида:
![]()
Параметр показывает, сколько составили бы дивиденды, начисленные по результатам деятельности при отсутствии влияния со стороны курсовой цены акций. На основе параметра можно сделать вывод, что при изменении курсовой цены акций на 1 руб. произойдет изменение дивидендов в ту же сторону на 0,01 млн. руб.
2. Рассчитаем линейный коэффициент парной корреляции и коэффициент детерминации.
Линейный коэффициент парной корреляции определим по формуле:
![]() ,
,
Определим и :

![]()
Коэффициент корреляции, равный 0,708, позволяет судить о тесной связи между результативным и факторным признаками ![]() .
.
Коэффициент детерминации равен квадрату линейного коэффициента корреляции:
![]()
Коэффициент детерминации показывает, что на вариации начисленных дивидендов зависит от вариации курсовой цены акций, и на - от остальных неучтенных в модели факторов.
3. Оценим значимость параметров уравнения регрессии и линейного коэффициента корреляции по t- критерию Стьюдента. Необходимо сравнить расчетные значения t- критерия для каждого параметра и сравнить его с табличным.
Для расчета фактических значений t -критерия определим :

Для коэффициентов регрессионного уравнения проверка их уровня значимости осуществляется по t -критерию Стьюдента и по критерию F Фишера. Ниже мы рассмотрим оценку достоверности показателей регрессии только для линейных уравнений (12.1) и (12.2).
Y=a 0 + a 1 X (12.1)
Х= b 0 + b 1 Y (12.2)
Для это типа уравнений оценивают по t -критерию Стьюдента только величины коэффициентов а 1и b 1с использованием вычисления величины Тф по следующим формулам:
Где r yx коэффициент корреляции, а величину а 1можно вычислить по формулам 12.5 или 12.7.
Формула (12.27) используется для вычисления величины Тф, а 1уравнения регрессии Y по X.

Величину b 1можно вычислить по формулам (12.6) или (12.8).
Формула (12.29) используется для вычисления величины Тф, которая позволяет оценить уровень значимости коэффициента b 1уравнения регрессии X по Y
Пример. Оценим уровень значимости коэффициентов регрессии а 1и b 1уравнений (12.17), и (12.18), полученных при решении задачи 12.1. Воспользуемся для этого формулами (12.27), (12.28), (12.29) и (12.30).
Напомним вид полученных уравнений регрессии:
Y х = 3 + 0,06 X (12.17)
X y = 9+ 1 Y (12.19)
Величина а 1в уравнении (12.17) равна 0,06. Поэтому для расчета по формуле (12.27) нужно подсчитать величину Sb y х. Согласно условию задачи величина п = 8. Коэффициент корреляции также уже был подсчитан нами по формуле 12.9: r xy = √ 0,06 0,997 = 0,244 .
Осталось вычислить величины Σ (у ι - y ) 2 и Σ (х ι –x ) 2 , которые у нас не подсчитаны. Лучше всего эти расчеты проделать в таблице 12.2:
Таблица 12.2
| № испытуемых п/п | х ι | у i | х ι –x | (х ι –x ) 2 | у ι - y | (у ι - y ) 2 |
| -4,75 | 22,56 | - 1,75 | 3,06 | |||
| -4,75 | 22,56 | -0,75 | 0,56 | |||
| -2,75 | 7,56 | 0,25 | 0,06 | |||
| -2,75 | 7,56 | 1,25 | 15,62 | |||
| 1,25 | 1,56 | 1,25 | 15,62 | |||
| 3,25 | 10,56 | 0,25 | 0,06 | |||
| 5,25 | 27,56 | -0,75 | 0,56 | |||
| 5,25 | 27,56 | 0,25 | 0,06 | |||
| Суммы | 127,48 | 35,6 | ||||
| Средние | 12,75 | 3,75 |
Подставляем полученные значения в формулу (12.28), получаем:
Теперь рассчитаем величину Тф по формуле (12.27):

Величина Тф проверяется на уровень значимости по таблице 16 Приложения 1 для t- критерия Стьюдента. Число степеней свободы в этом случае будет равно 8-2 = 6, поэтому критические значения равны соответственно для Р ≤ 0,05 t кр = 2,45 и для Р≤ 0,01 t кр =3,71. В принятой форме записи это выглядит так:

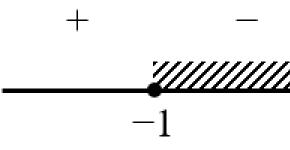
Строим «ось значимости»:

Полученная величина Тф Н о о том, что величина коэффициента регрессии уравнения (12.17) неотличима от нуля. Иными словами, полученное уравнение регрессии неадекватно исходным экспериментальным данным.
Рассчитаем теперь уровень значимости коэффициента b 1. Для этого необходимо вычислить величину Sb xy по формуле (12.30), для которой уже расчитаны все необходимые величины:
Теперь рассчитаем величину Тф по формуле (12.27):

Мы можем сразу построить «ось значимости», поскольку все предварительные операции были проделаны выше:

Полученная величина Тф попала в зону незначимости, следовательно мы должны принять гипотезу H о о том, что величина коэффициента регрессии уравнения (12.19) неотличима от нуля. Иными словами, полученное уравнение регрессии неадекватно исходным экспериментальным данным.
Нелинейная регрессия
Полученный в предыдущем разделе результат несколько обескураживает: мы получили, что оба уравнения регрессии (12.15) и (12.17) неадекватны экспериментальным данным. Последнее произошло потому, что оба эти уравнения характеризуют линейную связь между признаками, а мы в разделе 11.9 показали, что между переменными X и Y имеется значимая криволинейная зависимость. Иными словами, между переменными Х и Y в этой задаче необходимо искать не линейные, а криволинейные связи. Проделаем это с использованием пакета «Стадия 6.0» (разработка А.П. Кулаичева, регистрационный номер 1205).
Задача 12.2 . Психолог хочет подобрать регрессионную модель, адекватную экспериментальным данным, полученным в задаче 11.9.
Решение. Эта задача решается простым перебором моделей криволинейной регрессии предлагаемых в статистическом пакете Стадия. Пакет организован таким образом, что в электронную таблицу, которая является исходной для дальнейшей работы, заносятся экспериментальные данные в виде первого столбца для переменной X и второго столбца для переменной Y. Затем в основном меню выбирается раздел Статистики, в нем подраздел - регрессионный анализ, в этом подразделе вновь подраздел - криволинейная регрессия. В последнем меню даны формулы (модели) различных видов криволинейной регрессии, согласно которым можно вычислять соответствующие регрессионные коэффициенты и сразу же проверять их на значимость. Ниже рассмотрим только несколько примеров работы с готовыми моделями (формулами) криволинейной регрессии.
1. Первая модель - экспонента . Ее формула такова:
![]()
При расчете с помощью статпакета получаем а 0 = 1 и а 1 = 0,022.
Расчет уровня значимости для а, дал величину Р = 0,535. Очевидно, что полученная величина незначима. Следовательно, данная регрессионная модель неадекватна экспериментальным данным.
2. Вторая модель - степенная . Ее формула такова:
![]()
При подсчете а о = - 5,29, а, = 7,02 и а 1 = 0,0987.
Уровень значимости для а 1 - Р = 7,02 и для а 2 - Р = 0,991. Очевидно, что ни один из коэффициентов не значим.
3. Третья модель - полином . Ее формула такова:
Y = а 0 + а 1 X + а 2 X 2 + а 3 X 3
При подсчете а 0 = - 29,8, а 1 = 7,28, а 2 = - 0,488 и а 3 = 0,0103. Уровень значимости для а, - Р = 0,143, для а 2 - Р = 0,2 и для а, - Р= 0,272
Вывод - данная модель неадекватна экспериментальным данным.
4. Четвертая модель - парабола .
Ее формула такова: Y= a o + a l -X 1 + а 2 Х 2
При подсчете а 0 = - 9,88, а, = 2,24 и а 1 = - 0,0839 Уровень значимости для а 1 - Р = 0,0186, для а 2 - Р = 0,0201. Оба регрессионных коэффициента оказались значимыми. Следовательно, задача решена - мы выявили форму криволинейной зависимости между успешностью решения третьего субтеста Векслера и уровнем знаний по алгебре - это зависимость параболического вида. Этот результат подтверждает вывод, полученный при решении задачи 11.9 о наличии криволинейной зависимости между переменными. Подчеркнем, что именно с помощью криволинейной регрессии был получен точный вид зависимости между изучаемыми переменными.
Глава 13 ФАКТОРНЫЙ АНАЛИЗ
Основные понятия факторного анализа
Факторный анализ - статистический метод, который используется при обработке больших массивов экспериментальных данных. Задачами факторного анализа являются: сокращение числа переменных (редукция данных) и определение структуры взаимосвязей между переменными, т.е. классификация переменных, поэтому факторный анализ используется как метод сокращения данных или как метод структурной классификации.
Важное отличие факторного анализа от всех описанных выше методов заключается в том, что его нельзя применять для обработки первичных, или, как говорят, «сырых», экспериментальных данных, т.е. полученных непосредственно при обследовании испытуемых. Материалом для факторного анализа служат корреляционные связи, а точнее - коэффициенты корреляции Пирсона, которые вычисляются между переменными (т.е. психологическими признаками), включенными в обследование. Иными словами, факторному анализу подвергают корреляционные матрицы, или, как их иначе называют, матрицы интеркорреляций. Наименования столбцов и строк в этих матрицах одинаковы, так как они представляют собой перечень переменных, включенных в анализ. По этой причине матрицы интеркорреляций всегда квадратные, т.е. число строк в них равно числу столбцов, и симметричные, т.е. на симметричных местах относительно главной диагонали стоят одни и те же коэффициенты корреляции.
Необходимо подчеркнуть, что исходная таблица данных, из которой получается корреляционная матрица, не обязательно должна быть квадратной. Например, психолог измерил три показателя интеллекта (вербальный, невербальный и общий) и школьные отметки по трем учебным предметам (литература, математика, физика) у 100 испытуемых - учащихся девятых классов. Исходная матрица данных будет иметь размер 100 × 6, а матрица интеркорреляций размер 6 × 6, поскольку в ней имеется только 6 переменных. При таком количестве переменных матрица интеркорреляций будет включать 15 коэффициентов и проанализировать ее не составит труда.
Однако представим, что произойдет, если психолог получит не 6, а 100 показателей от каждого испытуемого. В этом случае он должен будет анализировать 4950 коэффициентов корреляции. Число коэффициентов в матрице вычисляется по формуле n (n+1)/2 и в нашем случае равно соответственно (100×99)/2= 4950.
Очевидно, что провести визуальный анализ такой матрицы - задача труднореализуемая. Вместо этого психолог может выполнить математическую процедуру факторного анализа корреляционной матрицы размером 100 × 100 (100 испытуемых и 100 переменных) и таким путем получить более простой материал для интерпретации экспериментальных результатов.
Главное понятие факторного анализа - фактор. Это искусственный статистический показатель, возникающий в результате специальных преобразований таблицы коэффициентов корреляции между изучаемыми психологическими признаками, или матрицы интеркорреляций. Процедура извлечения факторов из матрицы интеркорреляций называется факторизацией матрицы. В результате факторизации из корреляционной матрицы может быть извлечено разное количество факторов вплоть до числа, равного количеству исходных переменных. Однако факторы, выделяемые в результате факторизации, как правило, неравноценны по своему значению.
Элементы факторной матрицы называются или весами»; и они представляют собой коэффициенты корреляции данного фактора со всеми показателями, использованными в исследовании. Факторная матрица очень важна, поскольку она показывает, как изучаемые показатели связаны с каждым выделенным фактором. При этом факторный вес демонстрирует меру, или тесноту, этой связи.
Поскольку каждый столбец факторной матрицы (фактор) является своего рода переменной величиной, то сами факторы также могут коррелировать между собой. Здесь возможны два случая: корреляция между факторами равна нулю, в таком случае факторы являются независимыми (ортогональными). Если корреляция между факторами больше нуля, то в таком случае факторы считаются зависимыми (облическими). Подчеркнем, что ортогональные факторы в отличие от облических дают более простые варианты взаимодействий внутри факторной матрицы.
В качестве иллюстрации ортогональных факторов часто приводят задачу Л. Терстоуна, который, взяв ряд коробок разных размеров и формы, измерил в каждой из них больше 20 различных показателей и вычислил корреляции между ними. Профакторизовав полученную матрицу интеркорреляций, он получил три фактора, корреляция между которыми была равна нулю. Этими факторами были «длина», «ширина» и «высота».
Для того чтобы лучше уловить сущность факторного анализа, разберем более подробно следующий пример.
Предположим, что психолог у случайной выборки студентов получает следующие данные:
V 1 - вес тела (в кг);
V 2 - количество посещений лекций и семинарских занятий по предмету;
V 3 - длина ноги (в см);
V 4 - количество прочитанных книг по предмету;
V 5 - длина руки (в см);
V 6 - экзаменационная оценка по предмету (V - от английского слова variable - переменная).
При анализе этих признаков не лишено оснований предположение о том, что переменные V 1 , К 3 и V 5 - будут связаны между собой, поскольку, чем больше человек, тем больше он весит и тем длиннее его конечности. Сказанное означает, что между этими переменными должны получиться статистически значимые коэффициенты корреляции, поскольку эти три переменные измеряют некоторое фундаментальное свойство индивидуумов в выборке, а именно: их размеры. Точно так же вероятно, что при вычислении корреляций между V 2 , V 4 и V 6 тоже будут получены достаточно высокие коэффициенты корреляции, поскольку посещение лекций и самостоятельные занятия будут способствовать получению более высоких оценок по изучаемому предмету.
Таким образом, из всего возможного массива коэффициентов, который получается путем перебора пар коррелируемых признаков V 1 и V 2 , V t и V 3 и т.д., предположительно выделятся два блока статистически значимых корреляций. Остальная часть корреляций - между признаками, входящими в разные блоки, вряд ли будет иметь статистически значимые коэффициенты, поскольку связи между такими признаками, как размер конечности и успеваемость по предмету, имеют, скорее всего, случайный характер. Итак, содержательный анализ 6 наших переменных показывает, что они, по сути дела, измеряют только две обобщенные характеристики, а именно: размеры тела и степень подготовленности по предмету.
К полученной матрице интеркорреляций, т.е. вычисленным попарно коэффициентам корреляций между всеми шестью переменными V 1 - V 6 , допустимо применить факторный анализ. Его можно проводить и вручную, с помощью калькулятора, однако процедура подобной статистической обработки очень трудоемка. По этой причине в настоящее время факторный анализ проводится на компьютерах, как правило, с помощью стандартных статистических пакетов. Во всех современных статистических пакетах есть программы для корреляционного и факторного анализов. Компьютерная программа по факторному анализу по существу пытается «объяснить» корреляции между переменными в терминах небольшого числа факторов (в нашем примере двух).
Предположим, что, используя компьютерную программу, мы получили матрицу интеркорреляций всех шести переменных и подвергли ее факторному анализу. В результате факторного анализа получилась таблица 13.1, которую называют «факторной матрицей», или «факторной структурной матрицей».
Таблица 13.1
| Переменная | Фактор 1 | Фактор 2 |
| V 1 | 0,91 | 0,01 |
| V 2 | 0,20 | 0,96 |
| V 3 | 0,94 | -0,15 |
| V 4 | 0,11 | 0,85 |
| V 5 | 0,89 | 0,07 |
| V 6 | -0,13 | 0,93 |
По традиции факторы представляются в таблице в виде столбцов, а переменные в виде строк. Заголовки столбцов таблицы 13.1 соответствуют номерам выделенных факторов, но более точно было бы их называть «факторные нагрузки», или «веса», по фактору 1, то же самое по фактору 2. Как указывалось выше, факторные нагрузки, или веса, представляют собой корреляции между соответствующей переменной и данным фактором. Например, первое число 0,91 в первом факторе означает, что корреляция между первым фактором и переменной V 1 равна 0,91. Чем выше факторная нагрузка по абсолютной величине, тем больше ее связь с фактором.
Из таблицы 13.1 видно, что переменные V 1 V 3 и V 5 имеют большие корреляции с фактором 1 (фактически переменная 3 имеет корреляцию близкую к 1 с фактором 1). В то же время переменные V 2 , V 3 и У 5 имеют корреляции близкие к 0 с фактором 2. Подобно этому фактор 2 высоко коррелирует с переменными V 2 , V 4 и V 6 и фактически не коррелирует с переменными V 1 , V 3 и V 5
В данном примере, очевидно, что существуют две структуры корреляций, и, следовательно, вся информация таблицы 13.1 определяется двумя факторами. Теперь начинается заключительный этап работы - интерпретация полученных данных. Анализируя факторную матрицу, очень важно учитывать знаки факторных нагрузок в каждом факторе. Если в одном и том же факторе встречаются нагрузки с противоположными знаками, это означает, что между переменными, имеющими противоположные знаки, существует обратно пропорциональная зависимость.
Отметим, что при интерпретации фактора для удобства можно изменить знаки всех нагрузок по данному фактору на противоположные.
Факторная матрица показывает также, какие переменные образуют каждый фактор. Это связано, прежде всего, с уровнем значимости факторного веса. По традиции минимальный уровень значимости коэффициентов корреляции в факторном анализе берется равным 0,4 или даже 0,3 (по абсолютной величине), поскольку нет специальных таблиц, по которым можно было бы определить критические значения для уровня значимости в факторной матрице. Следовательно, самый простой способ увидеть какие переменные «принадлежат» фактору – это значит отметить те из них, которые имеют нагрузки выше, чем 0,4 (или меньше чем - 0,4). Укажем, что в компьютерных пакетах иногда уровень значимости факторного веса определяется самой программой и устанавливается на более высоком уровне, например 0,7.
Так, из таблицы 13.1, следует вывод, что фактор 1 - это сочетание переменных V 1 К 3 и V 5 (но не V 1 , K 4 и V 6 , поскольку их факторные нагрузки по модулю меньше чем 0,4). Подобно этому фактор 2 представляет собой сочетание переменных V 2 , V 4 и V 6 .
Выделенный в результате факторизации фактор представляет собой совокупность тех переменных из числа включенных в анализ, которые имеют значимые нагрузки. Нередко случается, однако, что в фактор входит только одна переменная со значимым факторным весом, а остальные имеют незначимую факторную нагрузку. В этом случае фактор будет определяться по названию единственной значимой переменной.
В сущности, фактор можно рассматривать как искусственную «единицу» группировки переменных (признаков) на основе имеющихся между ними связей. Эта единица является условной, потому что, изменив определенные условия процедуры факторизации матрицы интеркорреляций, можно получить иную факторную матрицу (структуру). В новой матрице может оказаться иным распределение переменных по факторам и их факторные нагрузки.
В связи с этим в факторном анализе существует понятие «простая структура». Простой называют структуру факторной матрицы, в которой каждая переменная имеет значимые нагрузки только по одному из факторов, а сами факторы ортогональны, т.е. не зависят друг от друга. В нашем примере два общих фактора независимы. Факторная матрица с простой структурой позволяет провести интерпретацию полученного результата и дать наименование каждому фактору. В нашем случае фактор первый - «размеры тела», фактор второй - «уровень подготовленности».
Сказанное выше не исчерпывает содержательных возможностей факторной матрицы. Из нее можно извлечь дополнительные характеристики, позволяющие более детально исследовать связи переменных и факторов. Эти характеристики называются «общность» и «собственное значение» фактора.
Однако, прежде чем представить их описание, укажем на одно принципиально важное свойство коэффициента корреляции, благодаря которому получают эти характеристики. Коэффициент корреляции, возведенный в квадрат (т.е. помноженный сам на себя), показывает, какая часть дисперсии (вариативности) признака является общей для двух переменных, или, говоря проще, насколько сильно эти переменные перекрываются. Так, например, две переменные с корреляцией 0,9 перекрываются со степенью 0,9 х 0,9 = 0,81. Это означает, что 81% дисперсии той и другой переменной являются общими, т.е. совпадают. Напомним, что факторные нагрузки в факторной матрице - это коэффициенты корреляции между факторами и переменными, поэтому, возведенная в квадрат факторная нагрузка характеризует степень общности (или перекрытия) дисперсий данной переменной и данного фактором.
Если полученные факторы не зависят друг от друга («ортогональное» решение), по весам факторной матрицы можно определить, какая часть дисперсии является общей для переменной и фактора. Вычислить, какая часть вариативности каждой переменной совпадает с вариативностью факторов, можно простым суммированием квадратов факторных нагрузок по всем факторам. Из таблицы 13.1, например, следует, что 0,91 × 0,91 + + 0,01 × 0,01 = 0,8282, т.е. около 82% вариативности первой переменной «объясняется» двумя первыми факторами. Полученная величина называется общностью переменной, в данном случае переменной V 1
Переменные могут иметь разную степень общности с факторами. Переменная с большей общностью имеет значительную степень перекрытия (большую долю дисперсии) с одним или несколькими факторами. Низкая общность подразумевает, что все корреляции между переменными и факторами невелики. Это означает, что ни один из факторов не имеет совпадающей доли вариативности с данной переменной. Низкая общность может свидетельствовать о том, что переменная измеряет нечто качественно отличающееся от других переменных, включенных в анализ. Например, одна переменная, связанная с оценкой мотивации среди заданий, оценивающих способности, будет иметь общность с факторами способностей близкую к нулю.
Малая общность может также означать, что определенное задание испытывает на себе сильное влияние ошибки измерения или крайне сложно для испытуемого. Возможно, напротив, также, что задание настолько просто, что каждый испытуемый дает на него правильный ответ, или задание настолько нечетко по содержанию, что испытуемый не понимает суть вопроса. Таким образом, низкая общность подразумевает, что данная переменная не совмещается с факторами по одной из причин: либо переменная измеряет другое понятие, либо переменная имеет большую ошибку измерения, либо существуют искажающие дисперсию признака различия между испытуемыми в вариантах ответа на это задание.
Наконец, с помощью такой характеристики, как собственное значение фактора, можно определить относительную значимость каждого из выделенных факторов. Для этого надо вычислить, какую часть дисперсии (вариативности) объясняет каждый фактор. Тот фактор, который объясняет 45% дисперсии (перекрытия) между переменными в исходной корреляционной матрице, очевидно, является более значимым, чем другой, который объясняет только 25% дисперсии. Эти рассуждения, однако, допустимы, если факторы ортогональны, иначе говоря, не зависят друг от друга.
Для того чтобы вычислить собственное значение фактора, нужно возвести в квадрат факторные нагрузки, и сложить их по столбцу. Используя данные таблицы 13.1 можно убедиться, что собственное значение фактора 1 составляет (0,91 × 0,91 + 0,20 × 0,20 + 0,94 × 0,94 + 0,11 × 0,11 + 0,84 × 0,84 + (- 0,13) ×
× (-0,13)) = 2,4863. Если собственное значение фактора разделить на число переменных (6 в нашем примере), то полученное число покажет, какая доля дисперсии объясняется данным фактором. В нашем случае получится 2,4863∙100%/6 = 41,4%. Иными словами, фактор 1 объясняет около 41% информации (дисперсии) в исходной корреляционной матрице. Аналогичный подсчет для второго фактора даст 41,5%. В сумме это будет составлять 82,9%.
Таким образом, два общих фактора, будучи объединены, объясняют только 82,9% дисперсии показателей исходной корреляционной матрицы. Что случилось с «оставшимися» 17,1%? Дело в том, что, рассматривая корреляции между 6 переменными, мы отмечали, что корреляции распадаются на два отдельных блока, и поэтому решили, что логично анализировать материал в понятиях двух факторов, а не 6, как и количество исходных переменных. Другими словами, число конструктов, необходимых, чтобы описать данные, уменьшилось с 6 (число переменных) до 2 (число общих факторов). В результате факторизации часть информации в исходной корреляционной матрице была принесена в жертву построению двухфакторной модели. Единственным условием, при котором информация не утрачивается, было бы рассмотрение шестифакторной модели.
После оценки индивидуальной статистической значимости каждого из коэффициентов регрессии обычно анализируется совокупная значимость коэффициентов, т.е. всего уравнения в целом. Такой анализ осуществляется на основе проверки гипотезы об общей значимости гипотезы об одновременном равенстве нулю всех коэффициентов регрессии при объясняющих переменных:
H 0: b 1 = b 2 = ... = b m = 0.
Если данная гипотеза не отклоняется, то делается вывод о том, что совокупное влияние всех m объясняющих переменных Х 1 , Х 2 , ..., Х m модели на зависимую переменную Y можно считать статистически несущественным, а общее качество уравнения регрессии – невысоким.
Проверка данной гипотезы осуществляется на основе дисперсионного анализа сравнения объясненной и остаточной дисперсии.
Н 0: (объясненная дисперсия) = (остаточная дисперсия),
H 1: (объясненная дисперсия) > (остаточная дисперсия).
Строится F-статистика:
где ![]() – объясненная регрессией дисперсия;
– объясненная регрессией дисперсия;
– остаточная дисперсия (сумма квадратов отклонений, поделённая на число степеней свободы n-m-1). При выполнении предпосылок МНК построенная F-статистика имеет распределение Фишера с числами степеней свободы n1 = m, n2 = n–m–1. Поэтому, если при требуемом уровне значимости a F набл > F a ; m ; n - m -1 = F a (где F a ; m ; n - m -1 - критическая точка распределения Фишера), то Н 0 отклоняется в пользу Н 1 . Это означает, что объяснённая регрессией дисперсия существенно больше остаточной дисперсии, а следовательно, уравнение регрессии достаточно качественно отражает динамику изменения зависимой переменной Y. Если F набл < F a ; m ; n - m -1 = F кр. , то нет основания для отклонения Н 0 . Значит, объясненная дисперсия соизмерима с дисперсией, вызванной случайными факторами. Это дает основание считать, что совокупное влияние объясняющих переменных модели несущественно, а следовательно, общее качество модели невысоко.
Однако на практике чаще вместо указанной гипотезы проверяют тесно связанную с ней гипотезу о статистической значимости коэффициента детерминации R 2:
Н 0: R 2 > 0.
Для проверки данной гипотезы используется следующая F-статистика:
![]() . (8.20)
. (8.20)
Величина F при выполнении предпосылок МНК и при справедливости H 0 имеет распределение Фишера, аналогичное распределению F-статистики (8.19). Действительно, разделив числитель и знаменатель дроби в (8.19) на общую сумму квадратов отклонений ![]() и зная, что она распадается на сумму квадратов отклонений, объяснённую регрессией, и остаточную сумму квадратов отклонений (это является следствием, как будет показано позже, системы нормальных уравнений)
и зная, что она распадается на сумму квадратов отклонений, объяснённую регрессией, и остаточную сумму квадратов отклонений (это является следствием, как будет показано позже, системы нормальных уравнений)
![]() ,
,
мы получим формулу (8.20):
Из (8.20) очевидно, что показатели F и R 2 равны или не равны нулю одновременно. Если F = 0, то R 2 = 0, и линия регрессии Y = является наилучшей по МНК, и, следовательно, величина Y линейно не зависит от Х 1 , Х 2 , ..., Х m . Для проверки нулевой гипотезы Н 0: F = 0 при заданном уровне значимости a по таблицам критических точек распределения Фишера находится критическое значение F кр = F a ; m ; n - m -1 . Нулевая гипотеза отклоняется, если F > F кр. Это равносильно тому, что R 2 > 0, т.е. R 2 статистически значим.
Анализ статистики F позволяет сделать вывод о том, что для принятия гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии коэффициент детерминации R 2 не должен существенно отличаться от нуля. Его критическое значение уменьшается при росте числа наблюдений и может стать сколь угодно малым.
Пусть, например, при оценке регрессии с двумя объясняющими переменными X 1 i , X 2 i по 30 наблюдениям R 2 = 0,65. Тогда
F набл = =25,07.
По таблицам критических точек распределения Фишера найдем F 0,05; 2; 27 = 3,36; F 0,01; 2; 27 = 5,49. Поскольку F набл = 25,07 > F кр как при 5%–м, так и при 1%–м уровне значимости, то нулевая гипотеза в обоих случаях отклоняется.
Если в той же ситуации R 2 = 0,4, то
F набл = = 9.
Предположение о незначимости связи отвергается и здесь.
Отметим, что в случае парной регрессии проверка нулевой гипотезы для F-статистики равносильна проверке нулевой гипотезы для t-статистики
коэффициента корреляции. В этом случае F-статистика равна квадрату t-статистики. Самостоятельную значимость коэффициент R 2 приобретает в случае множественной линейной регрессии.
8.6. Дисперсионный анализ для разложения общей суммы квадратов отклонений. Степени свободы для соответствующих сумм квадратов отклонений
Применим изложенную выше теорию для парной линейной регрессии.
После того, как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Оценка значимости уравнения регрессии в целом даётся с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен нулю, т.е. b = 0, и, следовательно, фактор х не оказывает влияния на результат у.
Непосредственному расчёту F-критерия предшествует анализ дисперсии. Центральное место в нём занимает разложение общей суммы квадратов отклонений переменной у от среднего значения на две части – “объяснённую” и “необъяснённую”:
Уравнение (8.21) является следствием системы нормальных уравнений, выведенных в одной предыдущих тем.
Доказательство выражения (8.21).
![]()
![]()
Осталось доказать, что последнее слагаемое равно нулю.
Если сложить от 1 до n все уравнения
y i = a+b×x i +e i , (8.22)
то получим åy i = a×å1+b×åx i +åe i . Так как åe i =0 и å1 =n, то получим
Тогда ![]() .
.
Если же вычесть из выражения (8.22) уравнение (8.23), то получим
В результате получим
![]()
![]()
![]()
Последние суммы равны нулю в силу системы двух нормальных уравнений.
Общая сумма квадратов отклонений индивидуальных значений результативного признака у от среднего значения вызвана влиянием множества причин. Условно разделим всю совокупность причин на две группы: изучаемый фактор х и прочие факторы. Если фактор на оказывает никакого влияния на результат, то линия регрессии параллельна оси OX и . Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадет с остаточной. Если же прочие факторы не влияют на результат, то у связана с х функционально и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объяснённая регрессией, совпадает с общей суммой квадратов.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс как обусловленный влиянием фактора х, т.е. регрессией у по х, так и вызванный действием прочих причин (необъяснённая вариация). Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации признака у приходится на объяснённую вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное влияние на признак у. Это равносильно тому, что коэффициент детерминации будет приближаться к единице.
Любая сумма квадратов связана с числом степеней свободы (df – degrees of freedom), с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант. Применительно к исследуемой проблеме число степеней свободы должно показать, сколько независимых отклонений из n возможных требуется для образования данной суммы квадратов. Так, для общей суммы квадратов требуется (n-1) независимых отклонений, ибо по совокупности из n единиц после расчёта среднего свободно варьируют лишь (n-1) число отклонений. Например, мы имеем ряд значений у: 1,2,3,4,5. Среднее из них равно 3, и тогда n отклонений от среднего составят: -2, -1, 0, 1, 2. Так как , то свободно варьируют лишь четыре отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
При расчёте объяснённой или факторной суммы квадратов ![]() используются теоретические (расчётные) значения результативного признака
используются теоретические (расчётные) значения результативного признака
Тогда сумма квадратов отклонений, обусловленных линейной регрессии, равна
Поскольку при заданном объёме наблюдений по x и y факторная сумма квадратов при линейной регрессии зависит только от константы регрессии b, то данная сумма квадратов имеет только одну степень свободы.
Существует равенство между числом степеней свободы общей, факторной и остаточной суммой квадратов отклонений. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет n-2. Число степеней свободы общей суммы квадратов определяется числом единиц варьируемых признаков, и поскольку мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, т.е. df общ. = n–1.
Итак, имеем два равенства:
Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или, что то же самое, дисперсию на одну степень свободы D.
 ;
;
 ;
;
 .
.
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчёте на одну степень свободы, получим величину F-критерия Фишера
где F-критерий для проверки нулевой гипотезы H 0: D факт = D ост.
Если нулевая гипотеза справедлива, то факторная и остаточная дисперсии не отличаются друг от друга. Для H 0 необходимо опровержение, чтобы факторная дисперсия превышала остаточную в несколько раз. Английским статистиком Снедекором разработаны таблицы критических значений F-отношений при различных уровнях существенности нулевой гипотезы и различном числе степеней свободы. Табличное значение F-критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношения признаётся достоверным, если оно больше табличного. Если F факт > F табл, то нулевая гипотеза H 0: D факт = D ост об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи.
Если F факт < F табл, то вероятность нулевой гипотезы H 0: D факт = D ост выше заданного уровня (например, 0,05) и она не может быть отклонена без серьёзного риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически незначимым. Гипотеза H 0 не отклоняется.
В рассматриваемом примере из главы 3:
![]() = 131200 -7*144002 = 30400 – общая сумма квадратов;
= 131200 -7*144002 = 30400 – общая сумма квадратов;
1057,878*(135,43-7*(3,92571) 2) = 28979,8 – факторная сумма квадратов;
![]() =30400-28979,8 = 1420,197 – остаточная сумма квадратов;
=30400-28979,8 = 1420,197 – остаточная сумма квадратов;
D факт = 28979,8;
D ост = 1420,197/(n-2) = 284,0394;
F факт =28979,8/284,0394 = 102,0274;
F a =0,05; 2; 5 =6,61; F a =0,01; 2; 5 = 16,26.
Поскольку F факт > F табл как при 1%-ном, так и при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
Величина F-критерия связана с коэффициентом детерминации . Факторную сумму квадратов отклонений можно представить как
![]() ,
,
а остаточную сумму квадратов – как
![]() .
.
Тогда значение F-критерия можно выразить как
 .
.
Оценка значимости регрессии обычно даётся в виде таблицы дисперсионного анализа
| Источники вариации | Число степеней свободы | Сумма квадратов отклонений | Дисперсия на одну степень свободы | F-отношение | |
| фактическое | Табличное при a=0,05 | ||||
| Общая | |||||
| Объяснённая | 28979,8 | 28979,8 | 102,0274 | 6,61 | |
| Остаточная | 1420,197 | 284,0394 | , его величина сравнивается с табличным значением при определённом уровне значимости α и числе степеней свободы (n-2).
Для оценки существенности, значимости коэффициента корреляции используется t-критерий Стьюдента.
Находится средняя ошибка коэффициента корреляции по формуле:
Н а
основе ошибки рассчитываетсяt-критерий:
а
основе ошибки рассчитываетсяt-критерий:
Рассчитанное значение t-критерия сравнивают с табличным, найденным в таблице распределения Стьюдента при уровне значимости 0,05 или 0,01 и числе степеней свободы n-1. Если расчетное значение t-критерия больше табличного, то коэффициент корреляции признается значимым.
При криволинейной связи для оценки значимости корреляционного отношения и уравнения регрессии применяется F-критерий. Он вычисляется по формуле:

или

где η – корреляционное отношение; n – число наблюдений; m – число параметров в уравнении регрессии.
Рассчитанное значение F сравнивается с табличным для принятого уровня значимости α (0,05 или 0,01) и чисел степеней свободы к 1 =m-1 и k 2 =n-m. Если расчетное значение F превышает табличное, связь признается существенной.
Значимость коэффициента регрессии устанавливается с помощью t-критерия Стьюдента, который вычисляется по формуле:

где σ 2 а i - дисперсия коэффициента регрессии.
Она вычисляется по формуле:

где к – число факторных признаков в уравнении регрессии.
Коэффициент регрессии признается значимым, если t a 1 ≥t кр. t кр отыскивается в таблице критических точек распределения Стьюдента при принятом уровне значимости и числе степеней свободы k=n-1.
4.3.Корреляционно-регрессионный анализ в Excel
Проведём корреляционно-регрессионный анализ взаимосвязи урожайности и затрат труда на 1 ц зерна. Для этого открываем лист Excel, в ячейки А1:А30 вводим значения факторного признака – урожайности зерновых культур, в ячейки В1:В30 значения результативного признака – затраттруда на 1 ц зерна. В меню Сервис выберем опцию Анализ данных. Щелкнув левой кнопкой мыши по этому пункту, откроем инструмент Регрессия. Щелкаем по кнопке OK, на экране появляется диалоговое окно Регрессия. В поле Входной интервал У вводим значения результативного признака (выделяя ячейки В1:В30), в поле Входной интервал Х вводим значения факторного признака (выделяя ячейки А1:А30). Отмечаем уровень вероятности 95%, выбираем Новый рабочий лист. Щелкаем по кнопке OK. На рабочем листе появляется таблица «ВЫВОД ИТОГОВ», в которой даны результаты вычисления параметров уравнения регрессии, коэффициента корреляции и другие показатели, позволяющие определить значимость коэффициента корреляции и параметров уравнения регрессии.
|
ВЫВОД ИТОГОВ | ||||||||
|
Регрессионная статистика | ||||||||
|
Множественный R | ||||||||
|
R-квадрат | ||||||||
|
Нормированный R-квадрат | ||||||||
|
Стандартная ошибка | ||||||||
|
Наблюдения | ||||||||
|
Дисперсионный анализ | ||||||||
|
Значимость F | ||||||||
|
Регрессия | ||||||||
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
Нижние 95,0% |
Верхние 95,0% |
|
|
Y-пересечение | ||||||||
|
Переменная X 1 | ||||||||
В данной таблице «Множественный R» - это коэффициент корреляции, «R-квадрат» - коэффициент детерминации. «Коэффициенты: Y-пересечение» - свободный член уравнения регрессии 2,836242; «Переменная Х1» – коэффициент регрессии -0,06654. Здесь имеются также значения F-критерия Фишера 74,9876, t-критерия Стьюдента 14,18042, «Стандартная ошибка 0,112121», которые необходимы для оценки значимости коэффициента корреляции, параметров уравнения регрессии и всего уравнения.
На основе данных таблицы построим уравнение регрессии: у х =2,836-0,067х. Коэффициент регрессии а 1 =-0,067 означает, что с повышением урожайности зерновых на 1 ц/га затраты труда на 1 ц зерна уменьшаются на 0,067 чел.-ч.
Коэффициент корреляции r=0,85>0,7, следовательно, связь между изучаемыми признаками в данной совокупности тесная. Коэффициент детерминации r 2 =0,73 показывает, что 73% вариации результативного признака (затрат труда на 1 ц зерна) вызвано действием факторного признака (урожайности зерновых).
В таблице критических точек распределения Фишера - Снедекора найдём критическое значение F-критерия при уровне значимости 0,05 и числе степеней свободы к 1 =m-1=2-1=1 и k 2 =n-m=30-2=28, оно равно 4,21. Так как рассчитанное значение критерия больше табличного (F=74.9896>4,21), то уравнение регрессии признаётся значимым.
Для оценки значимости коэффициента корреляции рассчитаем t-критерий Стьюдента:
В таблице критических точек распределения
Стьюдента найдём критическое значениеt-критерия
при уровне значимости 0,05 и числе степеней
свободы n-1=30-1=29,
оно равно 2,0452. Так как расчётное значение
больше табличного, то коэффициент
корреляции является значимым.
таблице критических точек распределения
Стьюдента найдём критическое значениеt-критерия
при уровне значимости 0,05 и числе степеней
свободы n-1=30-1=29,
оно равно 2,0452. Так как расчётное значение
больше табличного, то коэффициент
корреляции является значимым.
Оценка значимости уравнения множественной регрессии
Построение эмпирического уравнения регрессии является начальным этапом эконометрического анализа. Первое же построенное по выборке уравнение регрессии очень редко является удовлетворительным по тем или иным характеристикам. Поэтому следующей важнейшей задачей эконометрического анализа является проверка качества уравнения регрессии. В эконометрике принята устоявшаяся схема такой проверки.
Итак, проверка статистического качества оцененного уравнения регрессии проводится по следующим направлениям:
· проверка значимости уравнения регрессии;
· проверка статистической значимости коэффициентов уравнения регрессии;
· проверка свойств данных, выполнимость которых предполагалась при оценивании уравнения (проверка выполнимости предпосылок МНК).
Проверка значимости уравнения множественной регрессии, так же как и парной регрессии, осуществляется с помощью критерия Фишера. В данном случае (в отличие от парной регрессии) выдвигается нулевая гипотеза Н 0 о том, что все коэффициенты регрессии равны нулю (b 1 =0, b 2 =0, … , b m =0). Критерий Фишера определяется по следующей формуле:
где D факт - факторная дисперсия, объясненная регрессией, на одну степень свободы; D ост - остаточная дисперсия на одну степень свободы; R 2 - коэффициент множественной детерминации; т х в уравнении регрессии (в парной линейной регрессии т = 1); п - число наблюдений.
Полученное значение F-критерия сравнивается с табличным при определенном уровне значимости. Если его фактическое значение больше табличного, тогда гипотеза Но о незначимости уравнения регрессии отвергается, и принимается альтернативная гипотеза о его статистической значимости.
С помощью критерия Фишера можно оценить значимость не только уравнения регрессии в целом, но и значимость дополнительного включения в модель каждого фактора. Такая оценка необходима для того, чтобы не загружать модель факторами, не оказывающими существенного влияния на результат. Кроме того, поскольку модель состоит из несколько факторов, то они могут вводиться в нее в различной последовательности, а так как между факторами существует корреляция, значимость включения в модель одного и того же фактора может различаться в зависимости от последовательности введения в нее факторов.
Для оценки значимости включения дополнительного фактора в модель рассчитывается частный критерий Фишера F xi . Он построен на сравнении прироста факторной дисперсии, обусловленного включением в модель дополнительного фактора, с остаточной дисперсией на одну степень свободы по регрессии в целом. Следовательно, формула расчета частного F-критерия для фактора будет иметь следующий вид:
где R 2 yx 1 x 2… xi … xp - коэффициент множественной детерминации для модели с полным набором п факторов; R 2 yx 1 x 2… x i -1 x i +1… xp - коэффициент множественной детерминации для модели, не включающей фактор x i ; п - число наблюдений; т - число параметров при факторах x в уравнении регрессии.
Фактическое значение частного критерия Фишера сравнивается с табличным при уровне значимости 0,05 или 0,1 и соответствующих числах степеней свободы. Если фактическое значение F xi превышает F табл , то дополнительное включение фактора x i в модель статистически оправдано, и коэффициент «чистой» регрессии b i при факторе x i статистически значим. Если же F xi меньше F табл , то дополнительное включение в модель фактора существенно не увеличивает долю объясненной вариации результата у, и, следовательно, его включение в модель не имеет смысла, коэффициент регрессии при данном факторе в этом случае статистически незначим.
С помощью частного критерия Фишера можно проверить значимость всех коэффициентов регрессии в предположении, что каждый соответствующий фактор x i вводится в уравнение множественной регрессии последним, а все остальные факторы были уже включены в модель раньше.
Оценка значимости коэффициентов «чистой» регрессии b i по критерию Стьюдента t может быть проведена и без расчета частных F -критериев. В этом случае, как и при парной регрессии, для каждого фактора применяется формула
t bi = b i / m bi ,
где b i - коэффициент «чистой» регрессии при факторе x i ; m bi - стандартная ошибка коэффициента регрессии b i .